 Question posted in
Question posted in 

Kubernetes deployment contains 2 containers:
- Django application with Daphne, binded on Unix socket
- Nginx is in front of it as reverse proxy
UDS is shared as volume between app and Nginx container, Memory type.
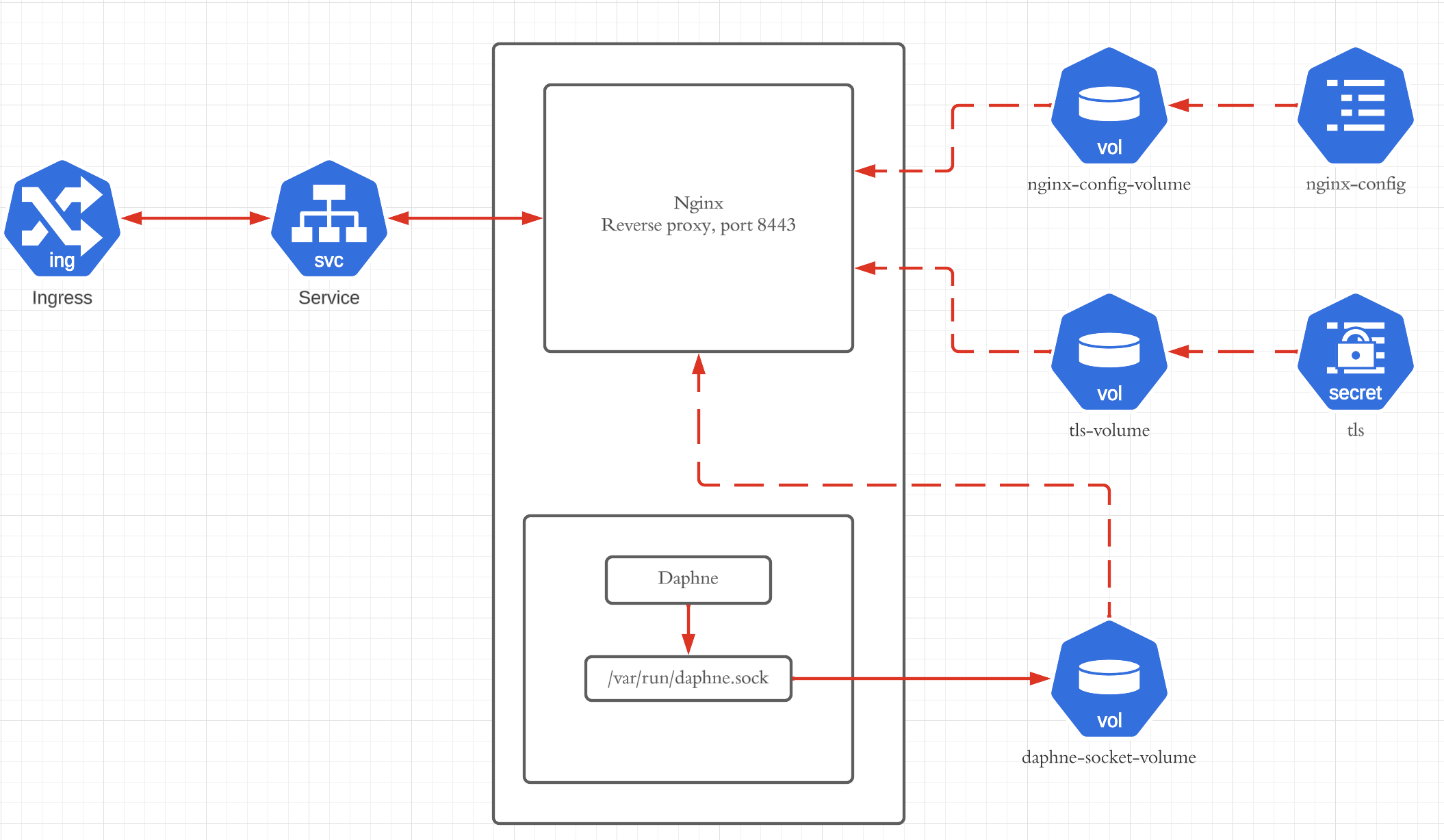
Configuration works as expected except when there are burst in connections, eg, when pod is restarted and all connections from killed pod are spreaded to remaining pods. When connections are being terminated, we can observe HTTP 502 errors that upstream server is not available on /var/run/daphne.sock. It lasts for some period, usually up to 20 seconds and it starts working again. If we switch to TCP port instead of UDS, it works slightly better, but 502 errors are still present.
Nginx config:
worker_processes 1;
user nobody nogroup;
error_log /var/log/nginx/error.log warn;
pid /tmp/nginx.pid;
events {
worker_connections 16384;
}
http {
include mime.types;
# fallback in case we can't determine a type
default_type application/octet-stream;
sendfile on;
access_log off;
upstream ws_server {
# fail_timeout=0 means we always retry an upstream even if it failed
# to return a good HTTP response
# for UNIX domain socket setups
server unix:/var/run/daphne.sock fail_timeout=0;
}
server {
listen 8443 ssl reuseport;
ssl_certificate /etc/nginx/ssl/TLS_CRT;
ssl_certificate_key /etc/nginx/ssl/TLS_KEY;
ssl_client_certificate /etc/nginx/ssl/CA_CRT;
ssl_protocols TLSv1.2 TLSv1.3;
client_max_body_size 5M;
client_body_buffer_size 1M;
keepalive_timeout 65;
location / {
access_log /dev/stdout;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $http_host;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_redirect off;
proxy_pass http://ws_server;
}
location /nginx_status {
stub_status on;
}
}
}
App is started as follows:
daphne app.asgi:application
-u /var/run/daphne.sock
--websocket_timeout 86400
--websocket_connect_timeout 30
Let’s assume we have 50000 websocket connections handled with 10 pods. AWS ALB is used in front of Nginx and on target group for this deployment I used least connection routing algorithm. As these connections are long living, we have, after some time, ~5000 connections per pod. Downscaling or restarting just one pod and spreading these ~5000 connections over 9 remaining pods (until new pod is ready for receiving traffic – passing liveness and readiness probes, and readiness gate) will result in high number of HTTP 502 errors.
Note: sending close when terminating websocket connections is not solution. Pod can be unexpectedly restarted , eg. because of OOM or faulty node…
Why idea why and how to mitigate this issue? It sounds silly that 9 pods cannot handle 5000 connections instantly.
2
Answers
Tried changing Nginx configuration to use worker_processes = 4, worker_connections = 4096, also, setting worker_rlimit_nofile to 32000, but this does not work anything different.
This is a known issue for the aws-load-balancer-controller, that the ALB might be sending requests to pods after ingress controller deregisters them.
When a pod is Terminating it will receive a SIGTERM connection asking it to finish up work and after that it will proceed with deleting the pod. At the same time that the pod starts terminating, the aws-load-balancer-controller will receive the updated object, forcing it to start removing the pod from the target group and to initialize draining.
Both of these processes – the signal handling at the kubelet level and the removal of the Pods IP from the TG – are decoupled from one another and the SIGTERM might have been handled before or at the same time, that the target in the target group has started draining.
As result the pod might be unavailable before the target group has even started its own draining process. This might result in dropped connections, as the LB is still trying to send requests to the properly shutdown pod. The LB will in-turn reply with 5xx responses.
You can follow the progress of the GitHub issue for resolution.