 Question posted in
Question posted in 

Introduction
Working on a Next.js 14 app where a user can paste content that he copied from an excel file into a spreadsheet-like component: react-data-grid. When copy-pasting on MacOS and Windows certain inconsistencies screw me over. Let’s take a look at the following example:
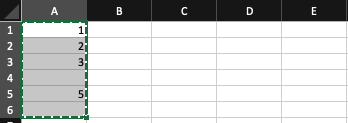
Goal, result and current approach
The goal for this example would be that I receive 6 cells: Rows divided by n and columns by r. but the actual result is as follows:
-
MacOS:
1rn2rn3rnrn5. The empty cell at the end is missing completely for MacOS whileris included even tho the selected area does not span over two columns. -
Windows:
1n2n3nnn. An additional line break is added at the end and thercharacters are absent. With the current approach the results vastly differ on each operating system:
const text = await navigator.clipboard.readText();
const rows = text.split("n")
const columns = breaks.map(line => line.split("r"));
// desired output would be [["1"], ["2"], ["3"], [""], ["5"], [""]]
//
// 1. MacOS output: [["1". ""], ["2", ""], ["3", ""], ["", ""], ["5"]]
//
// 2. Windows output: ["1"], ["2"], ["3"], [""], ["5"], [""], [""]]
While I definitely would be able to distinguish between the two operating system so I can handle accordingly, I can not figure out how to process these inconsistencies to reach the desired format.
2
Answers
After doing some investigation I now have the solution to properly handle the mentioned inconsistencies. This is the solution I have come up with.
As you can see in this example, each column has an equal amount of rows. The
rcharacter has been removed completely as it is not used. Interestingly thetcharacter started appearing in MacOS after restarting my machine and clearing my browser cache.I would be very interested to know which version of excel produced these results, as I did some digging myself in windows 10 and 11 and in both cases received a very uniform structure.
I recreated the spreadsheet in your screenshot and on CTRL-C got back:
"1n2n3nn5n"which can be quite easily parsed by a simple split (nested split for columns).
Additionally, column breaks were always separated by ‘t’ in my tests. I’d be curious to know why you’d assume a CR would be used, especially given its existing semantic significance. (I would’ve guessed the difference in OS is caused by unix CRLF discrepancy but the order is backwards for that).
As for your missing final cell, I’d assume its an optimisation detail. Is it critical to your logic to know how many cells were copied? Because otherwise, as far as I can see "copy until empty" would produce identical data in either case. Regardless, I’m guessing that specific detail is outright lost in translation unfortunately.