 Question posted in
Question posted in 

I’m new to web-scraping and I try to scrape the content from this website:INFOBANJIR JPS SELANGOR
This is the content that I’m trying to scrape:
ONLINE RAINFALL DATA (MM)
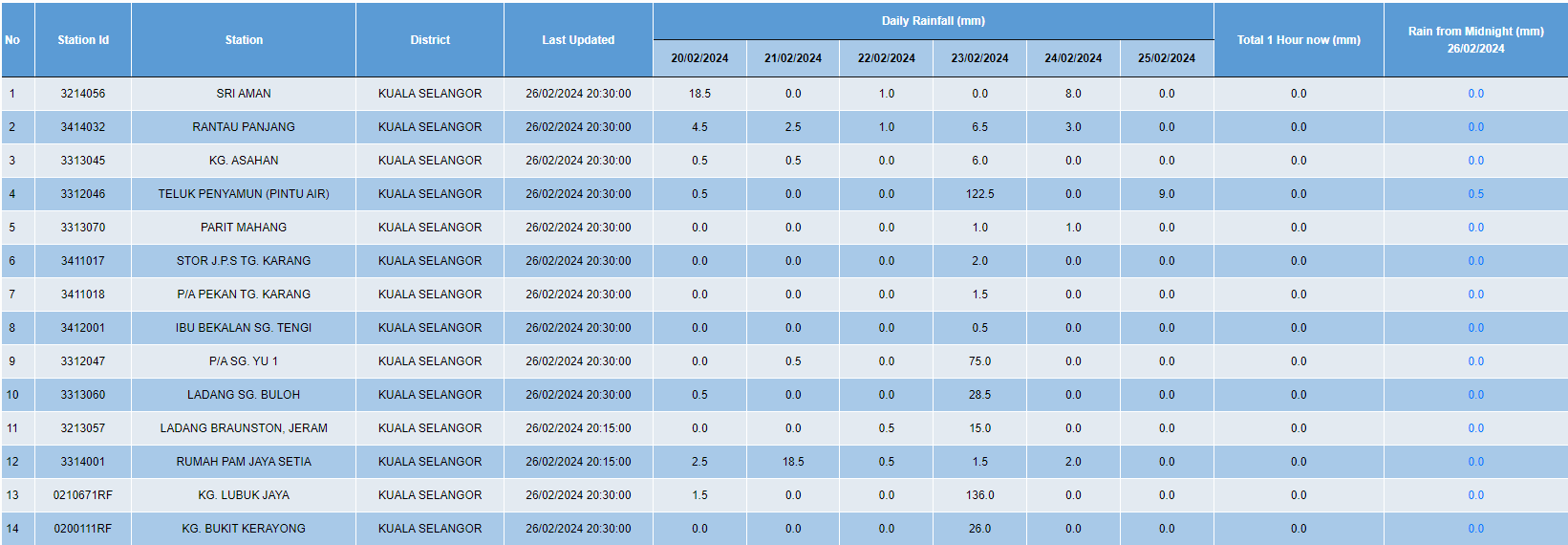{kind=link}
This is my code:
from bs4 import BeautifulSoup
import requests
url = 'http://infobanjirjps.selangor.gov.my/flood-gauge-data.html?districtId=4&lang=en'
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html')
soup.find_all('table', id='tableRainfall')
But, the output only shows this
Output
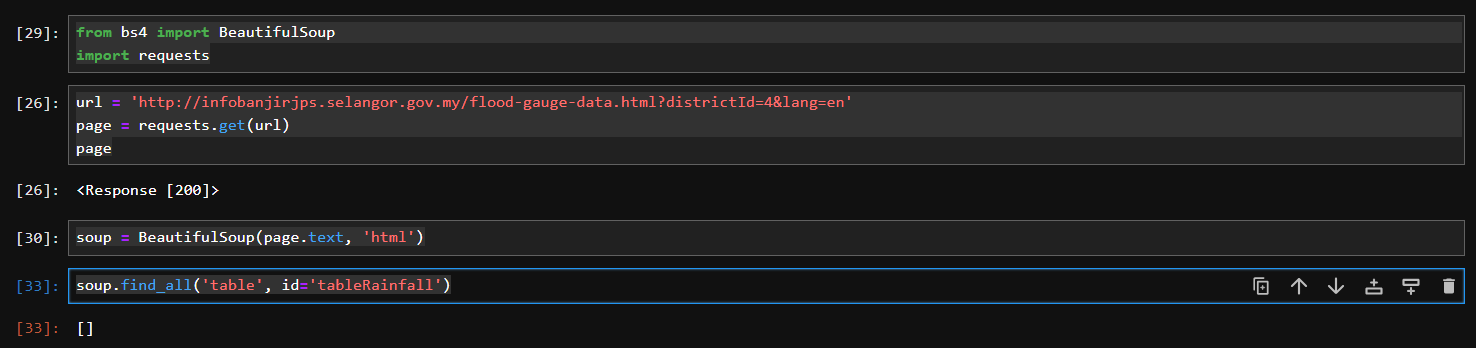{kind=link}
Then, I try to find the div by using id = ‘tableDataRainfall’, but still, the output shows the same thing as before.
It seems like the html inside of the division is missing. I’m sorry if it’s a stupid question, but I just wanna know why. Thank you in advance!
2
Answers
I’d be glad to help you with web scraping the content you’re interested in from the given website. However, I’m unable to access the specific content due to potential restrictions or limitations on the website itself. I’ll provide general guidance and best practices that you can adapt to your specific situation.
Understanding Dynamic Content Rendering:
JavaScript-Generated Content: If the content you’re trying to scrape is dynamically generated using JavaScript, the HTML structure might not be readily available in the initial page load. This means using BeautifulSoup directly on the fetched HTML might not yield the desired results.
Approaches for Dynamic Content Scraping:
Browser Automation (Selenium):
Install selenium and webdriver_manager using pip install selenium webdriver_manager.
Choose a suitable browser driver (e.g., chromedriver for Chrome) and set up the WebDriver path using webdriver_manager.ChromeDriverManager().install().
Create a Selenium WebDriver instance to control the browser and simulate user interactions.
Use JavaScript execution methods (e.g., execute_script) to wait for the content to be loaded dynamically.
Once the content is available, proceed with scraping using BeautifulSoup or other methods.
Python
Use code with caution.
API-Based Approach (if available):
Check if the website provides an API that offers access to the data you need. APIs are designed for programmatic data retrieval and often provide a structured format (e.g., JSON, XML) that’s easier to parse.
If an API is available, use appropriate libraries or tools (e.g., requests) to make API requests and handle the response data.
Important Considerations:
Respect website terms and conditions: Avoid overloading the website with excessive requests or violating scraping guidelines.
Handle potential errors: Implement error handling mechanisms to gracefully handle situations where the content might not be available or the scraping process encounters issues.
Be mindful of legal and ethical aspects: Ensure that your scraping activities comply with all applicable laws and regulations.
Remember to replace placeholders like "tableRainfall" with the actual IDs or selectors from the website you’re targeting. Adapt the code based on the website’s structure and the specific content you want to extract.
See this website for some information about dynamic web page scraping.
requestsandbeautifulSouparen’t enough to run JavaScript on a website; you need more powerful tools.