 Question posted in
Question posted in 

I’ve been playing around with PostgreSQL’s intarray module and I’ve noticed some seemingly odd behavior with intarrays that have duplicate elements in them. The intarray module defines two subtraction operators with pretty much the same description:
integer[] – integer → integer[] Removes entries matching the right argument from the array.
integer[] – integer[] → integer[] Removes elements of the right array from the left array.
To me, the wording above seems to imply that A[] - B[] is equivalent to FOR int i IN B[]: A[] -= i
Removing a single integer works as you’d expect, preserving duplicates:
SELECT '{3,1,1,2,2,2}'::int[] - 1 --> {3,2,2,2} (As expected)
Whereas removing an array removes all duplicates regardless:
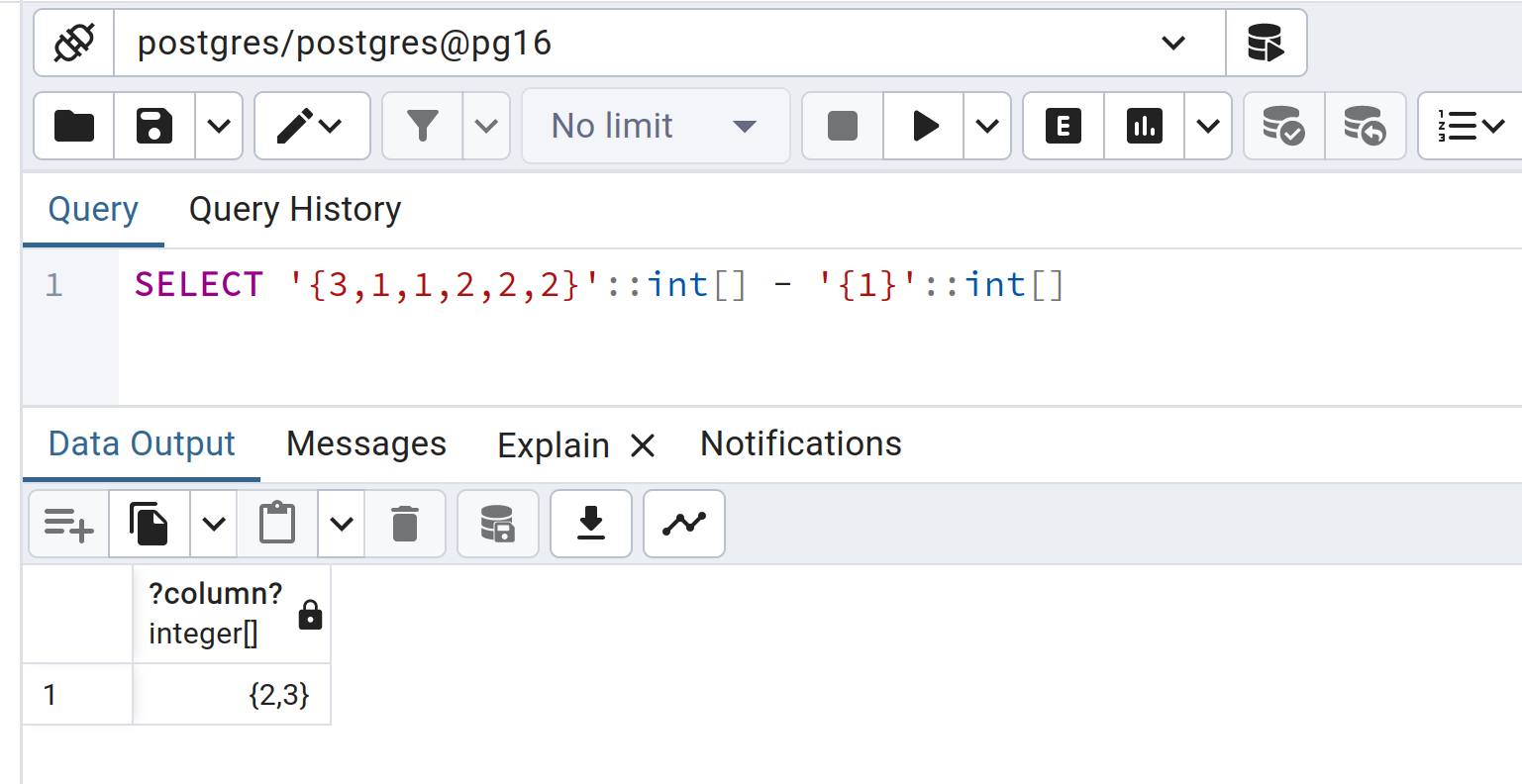
SELECT '{3,1,1,2,2,2}'::int[] - '{1}'::int[] --> {2,3} (Where's my extra twos???)
As of PG16, the intarray documentation doesn’t seem to mention anything about the automatic removal of ALL duplicated entries when computing the difference between two integer arrays (suggesting that it uses set operations under the hood – which is fine, but shouldn’t it say that?). So…
Is this the intended behavior when you subtract one integer array from another in PostgreSQL?
*For what I was doing, there was useful information stored in the number of duplicated elements in each array. While I was able to find a workaround for my application, it was still a surprise and took me a few minutes to figure out what was happening…
If it helps, I am running PostgreSQL 16.2 on Debian 12 (Specifically the official PostgreSQL Docker build of: PostgreSQL 16.2 (Debian 16.2-1.pgdg120+2) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit)
2
Answers
Yes, that is the intended behavior. At least, it has been like that since the introduction of the intarray extension. But I agree that some additional documentation wouldn’t harm.
In case that you often need a ‘plain behaviour’ array subtraction operator then you may define a custom one: