 Question posted in
Question posted in 

I have a dataset setup in my ADF solution which points to a blob container. There are 25 CSV files sitting in this container.
I have a dataflow setup in ADF which currently points to each .CSV file respectfully. For example, this csv is called Campus.csv however this file can come into the container as Campus20-02-24.csv – the date portion will always change.
So within the ADF Dataflow which looks like this below.
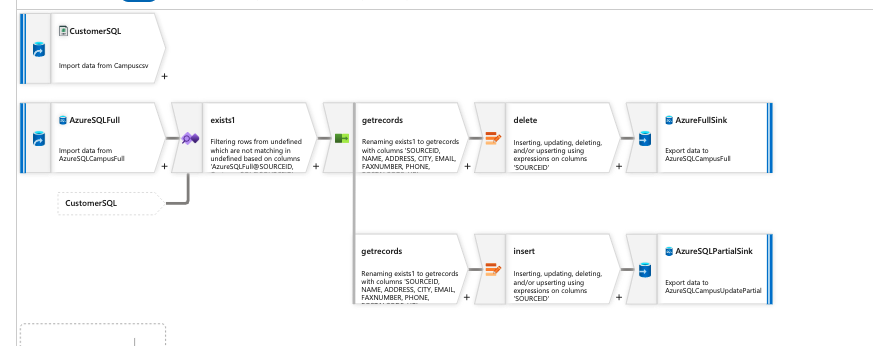{kind=link}
Now in the source connection, it points to the container and no specific CSV in that container, however I want it to connect to the Campus.csv file named like Campus20-02-24.csv so I am trying to understand the wild card path syntax to point to this source file i.e. location here below
Source Option below Wild Card Path
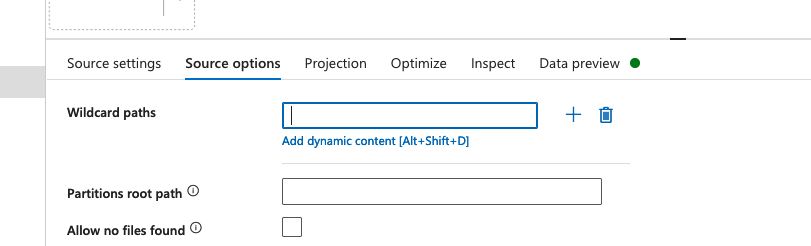{kind=link}
I have tried using /*/Campus20????????.csv where the Campus file will always have Campus20 + 8 date characters.csv.
This is the error I am getting when attempting to data preview the csv
Error when data previewing the results
{kind=link}
What syntax should i be using here please?
I have tried using a combination of the Container – blob – csv file alike wildcard name.
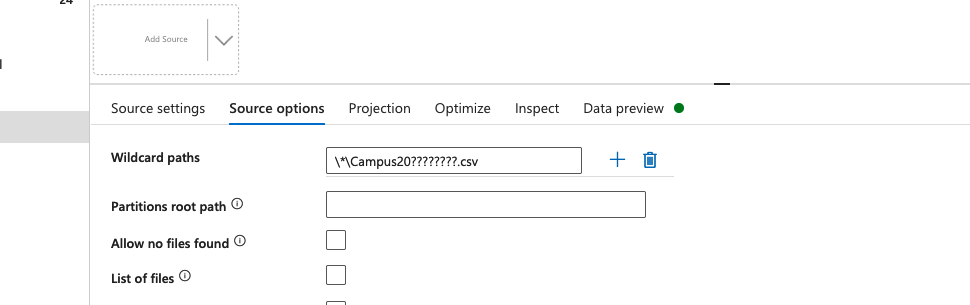{kind=link}
2
Answers
Instead of backslash
*Campus20????????.csv, please try forward slash/*/Campus20????????.csv. In the query you mentioned that you tried/*/Campus20????????.csv, however in screenshot it’s different.In case if you want to merge all the source files and transform them into target file, you can go ahead with @AnnuKumari’s answer.
But you have mentioned that your files pattern is like
Campus20-02-24.csvwhere there are only 6 characters after 20. If24represents year, change the pattern like this*/Campus??????24.csv.In the case of transforming each csv file into target files in each iteration, you can try the below approach.
First use a new dataflow to get the list of filepaths. Give the same wild card path
*/Campus??????24.csvin the source and set a column for the filepath like below. This will generate a new column and stores the filepaths of each csv file in its rows.Next use aggregate transformation and do group by on column
filepathand create a sample columncounton any column.Use select and remove the extra
countcolumn and add the sink after this.In the sink, select
cacheand check on Write to activity output. The dataflow output will give the required filepaths list of nested folders.Use this expression in the pipeline to get the filepaths array from dataflow output.
Go through this SO answer for the detail step by step procedure of the above.
Now, use this array and loop through the files and process each csv file as per your requirement in each iteration. Give the above expression to a for-each activity.
Inside For-each activity, give your dataflow activity. In your dataflow, go to your source dataset and create a string type parameter and give that to the filename as
@dataset().filepathlike below.In the dataflow activity, it will ask the value of this parameter. Now, pass each filename using
@item().filepathinside for-loop like below.The first dataflow will generate the list of filepaths and it will be passed to the for-each activity. Each csv file will be processed by your dataflow by this for-loop.