


I am seeing lot of this wait event in my AWS Aurora MySQL (8.0.mysql_aurora.3.04.0) and the documentation says "this event indicate an increase in workload activity. Increased activity means increased I/O", which causes spike in CPU usage.
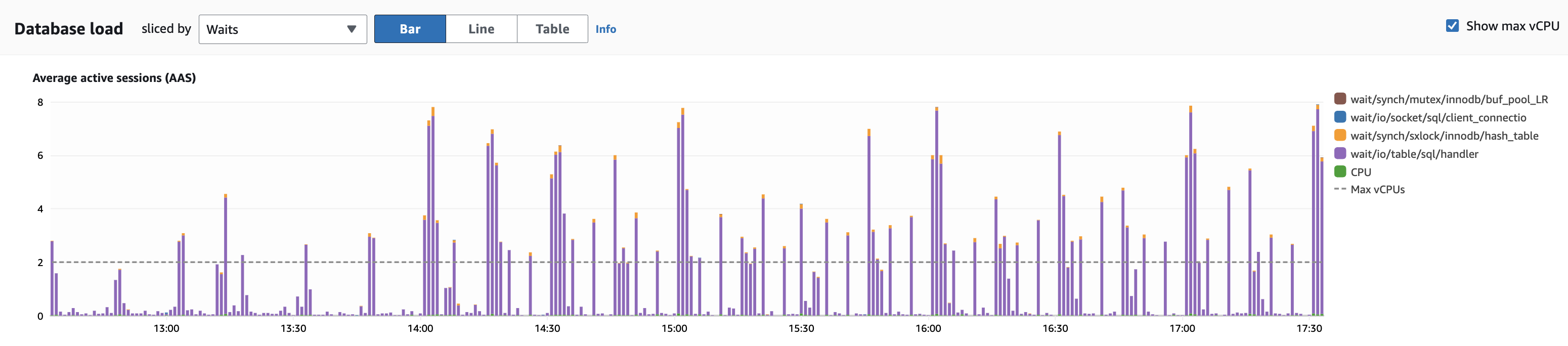
Note, the underlying query is ONLY a select statement running against the reader. we are an api based weather application and the parameters under "IN" clause can range from 1000 to 5000 [max_allowed_packets = 1GB] . Query scans the corresponding table (250GB) and uses proper index to retrieve the records and complete within seconds, sometime milliseconds. I am new to mysql and looking for some help on how to avoid/reduce the cpu spike by tweaking any configuration parameters.
PS: I am seeing spike in the following cloudwatch metrics on the DB Cluster
AuroraSlowConnectionHandleCount
AuroraReplicaLag
DBLoadNonCPU
ReadIOPS
ReadLatency
ReadThroughput
SelectLatency
edit: Query and plan — This table is not partitioned and returns around 200 rows( < 1% of total table rows). No DML activity on this db since its a reader instance.
CREATE TABLE `TABLE_NAME` (
`DATETIMES` bigint unsigned NOT NULL,
`S_ID` int unsigned NOT NULL,
`V_ID` smallint unsigned NOT NULL,
`NOS` int unsigned DEFAULT NULL,
`DELTA1` float DEFAULT NULL,
`DELTA2` int unsigned DEFAULT NULL,
`FLAGS` tinyint unsigned DEFAULT NULL,
`YEARS` float DEFAULT NULL,
PRIMARY KEY (`S_ID`,`DATETIMES`,`V_ID`),
KEY `DATETIMES` (`DATETIMES`,`S_ID`,`V_ID`,`NOS`,`DELTA1`,`DELTA2`,`FLAGS`,`YEARS`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
SELECT a.S_ID, a.V_ID, a.DATETIMES, a.YEARS, a.NOS
FROM DB_NAME.TABLE_NAME a
INNER JOIN (
SELECT S_ID, V_ID, max(DATETIMES) DATETIMES
FROM DB_NAME.TABLE_NAME force index(DATETIMES)
WHERE DATETIMES >= 202310161117 and DATETIMES <= 202310161317 and S_ID in (1,2,5,9,....,4890)
GROUP BY S_ID, V_ID
) b ON a.S_ID = b.S_ID AND a.V_ID = b.V_ID and a.DATETIMES = b.DATETIMES
-> Limit: 200 row(s) (cost=687820.47 rows=200) (actual time=621.565..622.059 rows=71 loops=1)
-> Nested loop inner join (cost=687820.47 rows=580086) (actual time=621.564..622.053 rows=71 loops=1)
-> Filter: (b.DATETIMES is not null) (cost=0.11..65262.18 rows=580086) (actual time=621.543..621.565 rows=71 loops=1)
-> Table scan on b (cost=2.50..2.50 rows=0) (actual time=0.001..0.010 rows=71 loops=1)
-> Materialize (cost=2.50..2.50 rows=0) (actual time=621.542..621.556 rows=71 loops=1)
-> Table scan on <temporary> (actual time=0.003..0.014 rows=71 loops=1)
-> Aggregate using temporary table (actual time=621.498..621.515 rows=71 loops=1)
-> Filter: ((TABLE_NAME.DATETIMES >= 202310161117) and (TABLE_NAME.DATETIMES <= 202310161317) and (TABLE_NAME.S_ID in (1,2,5,9,....,4890))) (cost=238947.80 rows=580086) (actual time=0.377..620.724 rows=713 loops=1)
-> Covering index range scan on TABLE_NAME using DATETIMES over (202310161117 <= DATETIMES <= 202310161317 AND 1 <= S_ID <= 4890) (cost=238947.80 rows=1160172) (actual time=0.021..520.516 rows=738696 loops=1)
-> Single-row index lookup on a using PRIMARY (S_ID=b.S_ID, DATETIMES=b.DATETIMES, V_ID=b.V_ID) (cost=0.97 rows=1) (actual time=0.007..0.007 rows=1 loops=71)
Appreciate your time!!
Generate query plan for the underlying query and confirmed its not doing table scan.
2
Answers
It seems that your main concern is spiking resource consumption, response time is not an issue.
I’m not a Mysql expert, but some general things below may be worth checking (based on my Oracle db background, its more about reducing cost than identifying the reason for the spikes)
Even if its not doing a table scan, the db indexes are generally best for returning a few rows from a large table rather than scanning (and returning) big chunks of it.
How many rows are returned by the query as a % of the total number of rows in the table? If it returns most of the rows, then benefit of using an index is less.
Does the query SELECT columns it does not even use ?
Is the table partitioned? Does its structure lend itself to partitioning, maybe it has a date-time column, which is also used in the SQL, and in this case partitioning pruning can reduce the amount of IO and resources consumed overall?
Does the table need some optimization or re-org?
Are there frequent intensive dml against it?
Hope that helps things along a bit.
Your large list
S_ID IN (large, list)induces the query planner to scan every row in the time range in the index you forced, rather than somehow selecting just the rows you need. That takes CPU and IO. It’s real work and you see those waits because sometimes the database server takes time to finish it.If this were my project I’d trust the query planner and stop forcing the choice of index. It’s possible the PK’s index (the clustered index) will be the right choice for some or all those long-list queries. And, those queries do take time. Those waits are due to that time. No weird index voodoo is going to change that.
If you do bulk table loads, do
ANALYZE TABLE TABLE_NAMEto update the optimizer statistics afterward. That may, or may not, help the query planner choose the best way to satisfy the query. (And do it once if you’ve never done it.)It might be possible to refactor your table design, especially if you have a limited set of those long lists your application uses. But only you know how that part of your data model