


I’m working on a data flow to ingest XML files and trying to pull a deeply nested node’s value up into another part of the flow. E.g.
<payload>
<header>
<customerID>1234</customerID>
<createdDate>1/2/2023T15:33:22</createdDate>
....
</header>
<body>
...
<compartments>
<compartment>
<compartmentNo>1</compartmentNo>
<product>2</product>
<quantity>5000</quantity>
...
<references>
<reference>
<referenceType>ShipmentID</referenceType>
<referenceValue>23434</referenceValue>
</reference>
<reference>
...
</reference>
</reference>
</compartment>
</compartments
</body>
</payload>
Note: This XML is not complete and also not a sensible structure but it’s what we’ve got from the vendor.
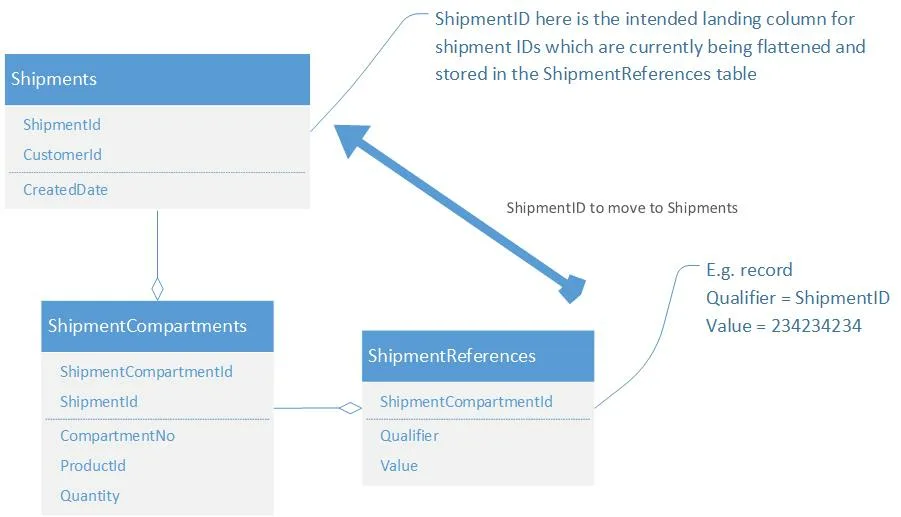
The file is ingested into 2 tables: Shipments and ShipmentCompartments however the ShipmentID belongs in the Shipments table.
I’m using a flattening activity to get all the compartments and then flattening references, but I’m unsure of how to get the shipment ID up to the Shipments Sinc activity especially since it is part of an array so I would need to get the correct Reference node (by filtering the referenceType by Shipment ID) and then extracting the value from the adjacent referenceValue node.
Source: XML File from a Blob storage container
Target: Azure SQL Server (split into multiple tables)
Table structure where data is currently being landed:
Any help would be appreciated.
2
Answers
body.compartments.compartmentwith the following configurations.customerID and createdDateas fixed mapping and a rule-based mapping to unpack the hierarchyreferences.reference:referenceTypevalues other thanShipmentID, you can use the filter transformation with conditionreferenceType=='ShipmentID'Azure SQL DB can read directly from blob store reading
OPENROWSET. A simple example:Other setup required:
Adapt this example for your requirement. Use ADF for orchestration and make use of the existing compute you have in the Azure SQL DB.