


Im having problem writting an azure function which takes blob input (JSON) and create a file using the contentbyte column from the JSON file.
JSON Template:
{
"@odata.context":"https://graph.microsoft.com/v1.0/$metadata#users('XXX.com')/messages('AQMkADAA3D%3D')/attachments",
"value":[
{
"@odata.type":"#microsoft.graph.fileAttachment",
"@odata.mediaContentType":"application/pdf",
"id":"AQMkADA0NjA5YT",
"lastModifiedDateTime":"2023-06-29T14:40:33Z",
"name":"MISC.pdf",
"contentType":"application/pdf",
"size":314000,
"isInline":false,
"contentId":"5E2D20ED5265174C8C9DC1AD59FFA4outlook.com",
"contentLocation":null,
"contentBytes":"JVBERi0xLjYNCiWAgYKDDQoxIDAgb2JqDQo8PCAvQ3JlYXRvciA8Pg0KL0NyZWF0aW9uRGF0ZSA8NDQzYTM[enter image description here](https://i.stack.imgur.com/WQJSz.png)y"
}
]
}
Azure Function:
{kind=link}
Below is the azure function i wrote:
import json
import base64
from base64 import *
import logging
import azure.functions as func
def main(req: func.HttpRequest,inputBlob: func.InputStream, outputBlob: func.Out[bytes]) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
try:
with open(inputBlob.read(),encoding='utf-8-sig') as user_file:
file_contents = user_file.read()
contents = json.loads(file_contents)
for file_contents in enumerate(contents.get("value")):
outputBlob.set(base64.b64decode(content.get("contentBytes")))
output = {"run":"success"}
return json.dumps(output)
except Exception as ex:
logging.exception(ex)
output = {"run":"failure"}
return json.dumps(output)
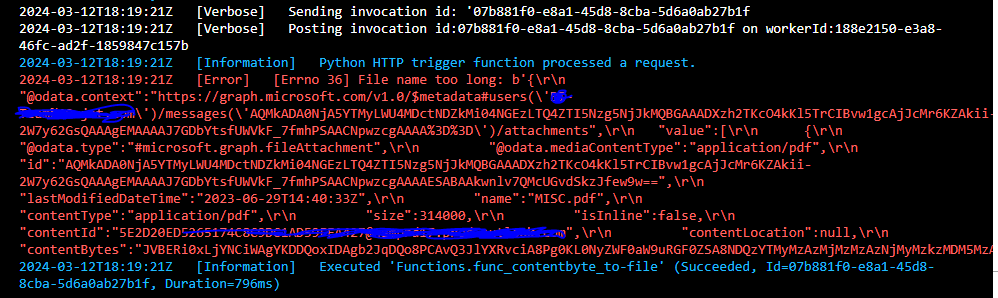
Below is the error msg"
[Error] [Errno 36] File name too long: b'{rn "@odata.context":"https://graph.microsoft.com/v1.0/$metadata#users('[email protected]')/messages('AQMkADA0NjA5YTMyLWU4MDctNDZkMi04
2
Answers
Thank you, Pavan. Your code helped me to identify the mistake i made. Below is the updated code I wrote which works great.
Now, I'm using the for loop because we have multiple JSON content in the file. So we may have multiple files. In the above case, since the OUPUT Blob I specified the file name, it continue to overwrite the Test.PDF file again and again. Can you please advise how to save the file with the name from the json?
"File name too long," typically occurs when you attempt to create a file with a name that exceeds the maximum allowed length for file names,
Ensure that the file name is not too long and does not contain any illegal characters.I have created Http trigger function with runtime stack python. I am able to create a file of content byte and sent to storage container by using output binding like below:
function code:
The output file is sent to storage container successfully. check below:
Output: