 Question posted in
Question posted in 

I have a column with data coming in as an string representation of an array
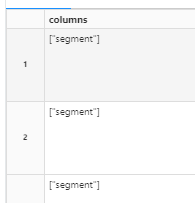
I tried to type cast it to an array type but the data is getting modified.
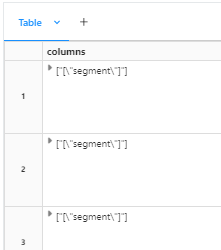
I tried to use regex as well to remove the extra brackets but its not working.
attaching the code below
This code is to convert the string representation of array to actual array
df = df.withColumn("columns", split(df["columns"], ", "))
This is the regex code i tried
df = df.withColumn(
'columns',
expr("transform(split(columns, ','), x -> trim('"[]', x))")
)
would really appreciate any help
3
Answers
Following is one possible way to do it.
Output :
Simple, You can use
from_jsonwitharray<string>schemaI have tried the following approach:
In the above code, I defined the schema for the array using
ArrayType(StringType()). Next, I specified that the array contains strings.Using the
withColumnmethod, combined withfrom_json, I transformed the "columns" column into an array of strings based on the specified schema.Results: