


I have a function that takes a dataframe as a parameter and calculates the NULL value counts and NULL value percentage and returns a dataframe with column_name, null value count and null percentages. How can I register it as UDF in pyspark so that I can use the spark’s processing advantage. I am using spark 3.3.0
This is my function:
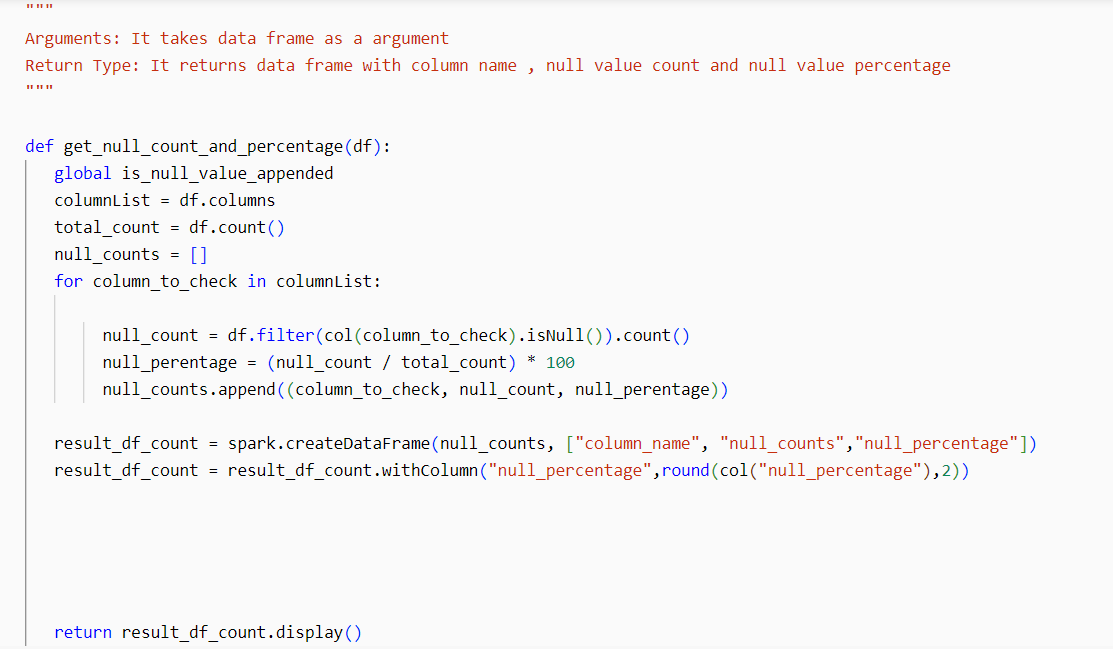
I could’nt find any method or implementation for complex functions and functions that run on whole dataframe.
2
Answers
encountered Serialization Issues,Missing GROUP BY
Clause,Incompatible Data Types and Unsupported Functions
I have tried below approach
Created a function to get null count and percentage and called the function
df.count()col(column_to_check).isNull().spark.createDataFrame by passing the null_counts list, and the schema is defined as
['column_name', 'null_counts', 'null_percentage'].percentage of null values for each column in the DataFrame.
The function you made is not UDF. You are using spark methods inside the function so it is not UDF. Spark methods are already optimized for datasets.