


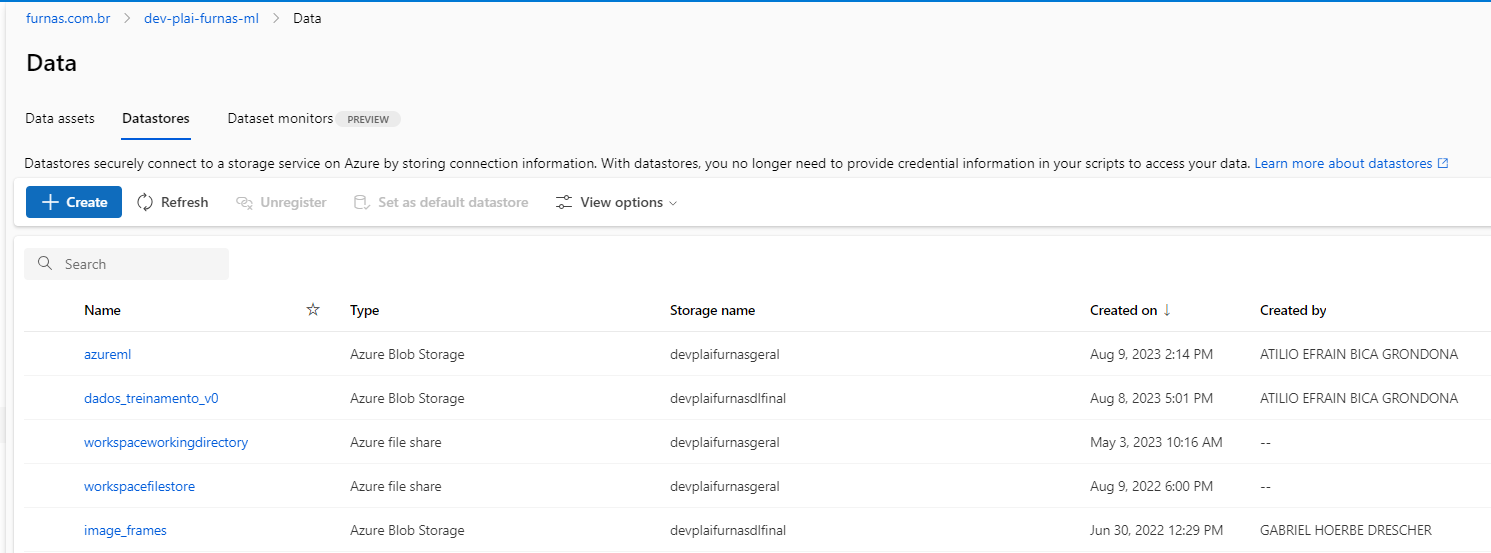
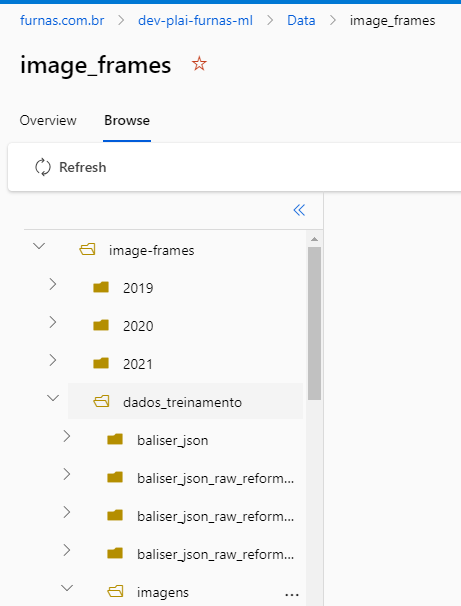
I am new with azure machine learning and I confess that I’m a little lost. I have a datastore named image_frames with contain a subfolder named imagens (IMAGE 01 and 02) with all the images that I will use for training and validation in an object detection model. There is a .jsonl file named object_annotations_normalized.jsonl that is in the same level of the imagens folder in the datastore.
- image_frames
|--- dados_treinamnto
| |--- imagens
| |--- object_annotations_normalized.jsonl
I am using this tutorial as guide:
https://github.com/retkowsky/azure_automl_for_images_python_sdk_v2/blob/main/AutoML%20for%20Images%20-%20Mask%20Object%20Detection%20-%20AzureML%20sdkV2.ipynb
that is similar to the documentation in azure:
https://learn.microsoft.com/en-us/azure/machine-learning/tutorial-auto-train-image-models?view=azureml-api-2&tabs=python
My problem is that I can’t figure out how to pass the folder imagens in the datastore image_frames to the code to run the experiment. It is not clear to me yet if I need to register this as an Data Asset first, and how I split the data in validation and training.
Below is the code that I am trying to adapt to run this experiment from the VScode on my local computer to execute it in the cloud:
import sys, os
import platform
import psutil
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.automl import SearchSpace, ObjectDetectionPrimaryMetrics
from azure.ai.ml.sweep import (Choice, Uniform, BanditPolicy,)
from azure.ai.ml import automl
from azure.ai.ml.entities import AmlCompute
from azure.core.exceptions import ResourceNotFoundError
sid = "xxxxxxxxxxx" # Azuresubscription
rg = "yyyyyyyyyyy" # Azure ML workspace resource group
ws = "zzzzzzzzzzzzzz" # Azure ML workspace
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
subscription_id = sid
resource_group = rg
workspace = ws
ml_client = MLClient(credential,
subscription_id,
resource_group,
workspace)
datastore = "image_frames"
subfolder_name = "dados_treinamento/imagens/"
# Create a Data Asset for your data in Blob Storage
###################################################
################# DOUBT I #########################
# HERE I CREATE A DATA ASSET POINTING THE DATA() CLASS
# TO A "SUBFOLDER" IN A CONTAINER AT STORAGE ACCOUNT
my_data = Data(
path = f'azureml://subscriptions/8e035c68-9f94597f2fc7/resourcegroups/dev-rg/workspaces/dev-furnas-ml/datastores/{datastore}/paths/{subfolder_name}',
type=AssetTypes.URI_FOLDER,
description="helicopter images Object detection",
name="test-fine-tunning-object-detection",)
####################################################
# THE TUTORIAL CREATE A DATA ASSET BUT IN MY CASE I THINK (NOT
# SURE) THAT I ONLY NEED TO RETRIEV IT
uri_blob_data_asset = ml_client.data.create_or_update(my_data)
compute_name = "devpipe-run"
try:
_ = ml_client.compute.get(compute_name)
print("Found existing compute target.")
except ResourceNotFoundError:
print("Creating a new compute target...")
compute_config = AmlCompute(
name=compute_name,
type="amlcompute",
size="Standard_NC6",
idle_time_before_scale_down=120,
min_instances=0,
max_instances=4,)
ml_client.begin_create_or_update(compute_config).result()
exp_name = "test-vscode-fine-tunning-objectdetection"
###################################################
################# DOUBT II ########################
# HERE I WANT TO SPLIT my_data CREATED WITH DATA()
# CLASS USING 80%-20% FOR TRAINING AND VALIDATION
my_training_data_input = Input(type=AssetTypes.MLTABLE, path=train_data_path)
my_validation_data_input = Input(type=AssetTypes.MLTABLE, path=valid_data_path)
####################################################
image_object_detection_job = automl.image_object_detection(
compute=compute_name,
experiment_name=exp_name,
training_data=my_training_data_input,
validation_data=my_validation_data_input,
target_column_name="label",
primary_metric="mean_average_precision",
tags={"my_custom_tag": "My custom value"},)
image_object_detection_job.set_limits(
max_trials=5,
max_concurrent_trials=2,)
returned_job = ml_client.jobs.create_or_update(
image_object_detection_job)
ml_client.jobs.stream(returned_job.name)
My doubts are in the comented parts of the code. I have so many questions about his.
- I need to create 2 data asset with the class Data() one for training and one for validation?
- I need register the folder imagens as a Data Asset? If yes how do I do this?
- Can I split the data into training and validation directly from the datastore image-frames? If yes how do I do it?
- In the DOUBT II, if we use the INPUT() class, how I pass the path?
- How I link the .jsonl annotation files with the image data in the folder imagens at image_frame datastore?
Sorry for my ignorance and for so many stupid questions, I’m still learning the concepts of data assets, data store, when register it, and many things related.
Even I knowing and understanding the theoretical basis of DNN the use of azure and cloud is tottaly new for me.
If someone can help me and give me some clarification of how to correct the code to performe the training a will appreciate a lot.
2
Answers
The answer do not solve the problem, and we move to another way to try to avoid this problem.
To create data asset from existing folder in datastores, you can use the directly create data asset from options in your datastore.
Another method is by using the Datastore URI.
You can use below code snippet to create data asset with URI of your data folder.
To answer your question,
You can use the same data asset for both training and validation.
For details regarding the train and validation split and creating MLTable data input you can check this sample notebook.