


I am trying to use the result of data frame that I generated from Azure Blob Storage and apply to the next step (where it extracts data in certain way).
I have tested both sides (generating data from Azure Blob Storage & extracting data using Regex (and it works if I tested separately)), but my challenge now is putting two pieces of code together.
Here is first part (getting data frame from Azure Blob Storage):
import re
from io import StringIO
import pandas as pd
from azure.storage.blob import BlobClient
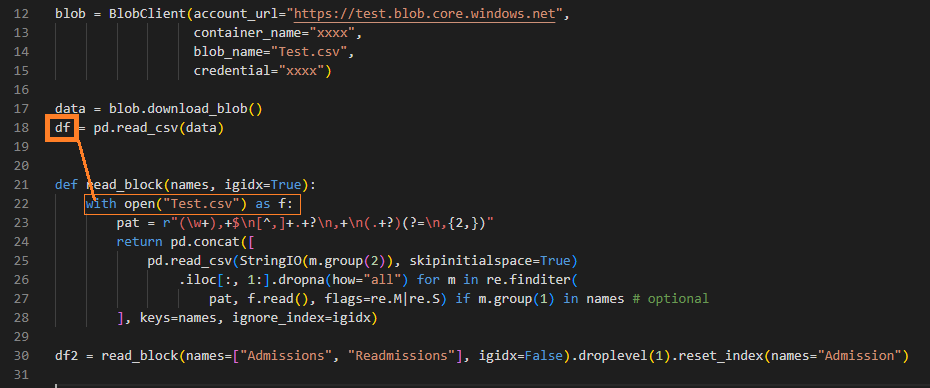
blob = BlobClient(account_url="https://test.blob.core.windows.net",
container_name="xxxx",
blob_name="Text.csv",
credential="xxxx")
data = blob.download_blob()
df = pd.read_csv(data)
Here is second part (extracting only some parts from a csv file):
def read_block(names, igidx=True):
with open("Test.csv") as f: ###<<<This is where I would like to modify<<<###
pat = r"(w+),+$n[^,]+.+?n,+n(.+?)(?=n,{2,})"
return pd.concat([
pd.read_csv(StringIO(m.group(2)), skipinitialspace=True)
.iloc[:, 1:].dropna(how="all") for m in re.finditer(
pat, f.read(), flags=re.M|re.S) if m.group(1) in names # optional
], keys=names, ignore_index=igidx)
df2 = read_block(names=["Admissions", "Readmissions"],igidx=False).droplevel(1).reset_index(names="Admission")
So, what I am trying to do is use df from the first code and apply into the input section of second code where it says "with open ("Test.csv") as f.
How do I modify the second part of this code to take the data result from first part?
Or if that does not work, is there a way to use the file path ID (data) generated from Azure like below?
<azure.storage.blob._download.StorageStreamDownloader object at 0x00000xxxxxxx>
Update:
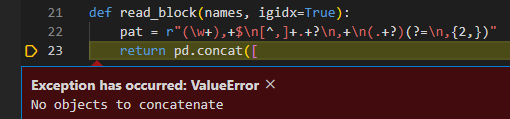
I modified the code as below, and now I am getting concat error:
I am not sure it is due to not having any looping function (as I modified to delete "with open("Test.csv") as f:).
...
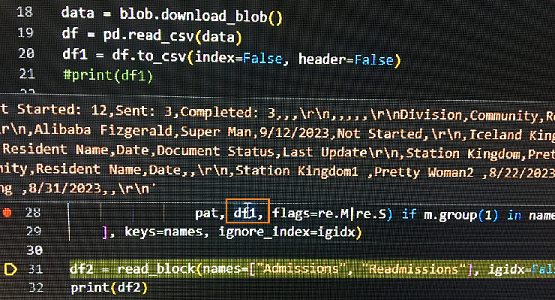
data = blob.download_blob()
df = pd.read_csv(data)
df1 = df.to_csv(index=False, header=False)
def read_block(names, igidx=True):
pat = r"(w+),+$n[^,]+.+?n,+n(.+?)(?=n,{2,})"
return pd.concat([
pd.read_csv(StringIO(m.group(2)), skipinitialspace=True)
.iloc[:, 1:].dropna(how="all") for m in re.finditer(
pat, df1, flags=re.M|re.S) if m.group(1) in names
], keys=names, ignore_index=igidx)
df2 = read_block(names=["Admissions", "Readmissions"], igidx=False).droplevel(1).reset_index(names="Admission")
print(df2)
New Image:
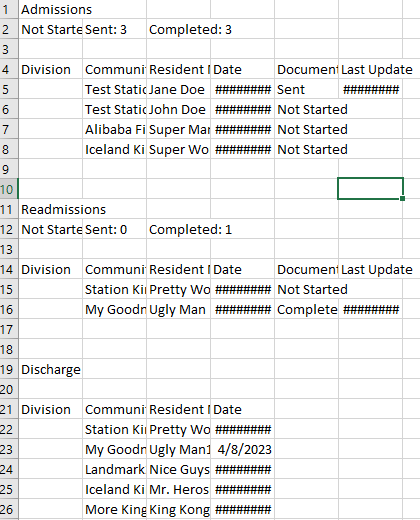
This is df1:
Not Started: 12,Sent: 3,Completed: 3,,,
,,,,,
Division,Community,Resident Name,Date,Document Status,Last Update
,Test Station,Jane Doe ,9/12/2023,Sent,9/12/2023
,Test Station 2,John Doe,9/12/2023,Not Started,
,Alibaba Fizgerald,Super Man,9/12/2023,Not Started,
,Iceland Kingdom,Super Woman,9/12/2023,Not Started,
,,,,,
,,,,,
Readmissions,,,,,
Not Started: 1,Sent: 0,Completed: 1,,,
,,,,,
Division,Community,Resident Name,Date,Document Status,Last Update
,Station Kingdom,Pretty Woman ,9/12/2023,Not Started,
,My Goodness,Ugly Man,7/21/2023,Completed,7/26/2023
,,,,,
,,,,,
Discharge,,,,,
,,,,,
Division,Community,Resident Name,Date,,
,Station Kingdom1 ,Pretty Woman2 ,8/22/2023,,
,My Goodness1 ,Ugly Man1,4/8/2023,,
,Landmark2,Nice Guys,9/12/2023,,
,Iceland Kingdom2,Mr. Heroshi2,7/14/2023,,
,More Kingdom 2,King Kong ,8/31/2023,,
This is the image csv file (that data gets generated into df1):
This is latest error message:
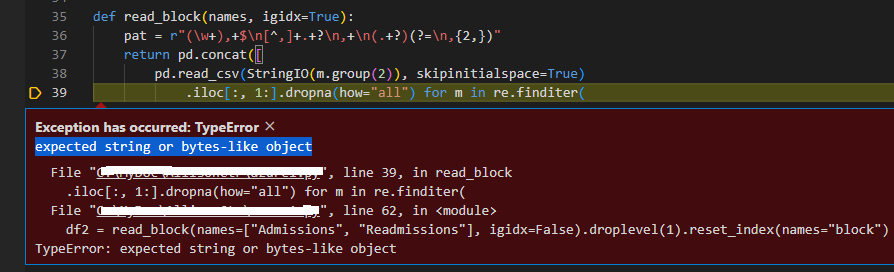
This is my latest code (11/13/2023-1):
import re
from io import StringIO
import pandas as pd
from azure.storage.blob import BlobClient
blob =
BlobClient(account_url="https://xxxx.blob.core.windows.net",
container_name="xxxx",
blob_name="SampleSafe.csv",
credential="xxxx")
data = blob.download_blob();
df = pd.read_csv(data);
df1 = df.to_csv(index=False)
def read_block(names, igidx=True):
pat = r"(w+),+$n[^,]+.+?n,+n(.+?)(?=n,{2,})"
return pd.concat([
pd.read_csv(StringIO(m.group(2)), skipinitialspace=True)
.iloc[:, 1:].dropna(how="all") for m in re.finditer(
pat, data.readall(), flags=re.M|re.S)
if m.group(1) in names], keys=names, ignore_index=igidx)
df2 = read_block(names=["Admissions", "Readmissions"], igidx=False).droplevel(1).reset_index(names="block")
print(df2)
This is detailed error message (updated 11/13/2023-1):

2
Answers
IIUC, that’s because regex fails to match the required blocks. You need to remove
header=Falsewhen making the bufferdf1 = df.to_csv(index=False). Or simplyreadallthe downloaded blob and make a string to avoid reading the input csv as a DataFrame :I think you’re making life too hard by trying to regex match the strings. Better to start with your original
dfand extract rows and columns from it:Output: