 Question posted in
Question posted in 

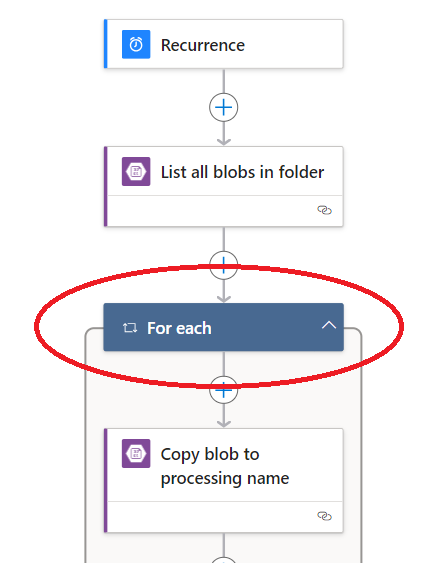
So, Azure Workflow editor does me the "courtesy" of creating a For Each iterator when I pull the list of files in a blob folder. But! What I want is a For One action. Is there an add action that allows me to just process one of the files in the list that results from the prior action?
2
Answers
Alright, so as of this moment, I'm confident that the answer to this question is No. Rithwikbojja stated that above in the comments, and my work on this brings me to agreement. There are not "state of blob list" functions available like exists_in_list or length_of_list or list_is_empty. All functions provided apply to a single item within the list.
Oh, and terminate functions don't run within loops for some reason. So you'll loop through everything, every time.
That said, you can do plenty of loops through the list of blobs, one after the other, in order to gain the information you need to eventually perform a process on all of the objects that only has an effect on one. In my case all I needed to do was to find a file by name and, if it doesn't exist, rename one of the blob files to that name.
So for me this was the following --
Get the list of blobs.
Loop through the list of blobs. 2a. On each pass of the loop, determine if the name of the blob is the name I'm looking for, true or false. 2b. On each pass of the loop, copy the name of the current blob into a variable.
. . . The result of this loop is that at some point a "file found" variable gets set to true if the file exists. The variable is initialized to false before the loop, gets set to true in one pass if the file name is found.
The name of each file gets written into a "file name to process" variable. It's set each pass through the loop, ending up with the last file name in the list as its final value. Sigh . . . not sweet programming, but it gets all my bs set up for the real pass. So far I've done no real work, just gotten stuff set up.
Loop through the list of blobs again. 3a. On each pass, IF the current blob has the "file name to process" AND "file found" is false, then copy that blob to the target file name, make a copy to an archive folder, and delete that blob from the folder. 3b. If the conditions in 3a are not met, do nothing.
. . . That is, loop through the entire set no matter what, doing nothing, except for that one place (last pass through the loop) where the file name matches, and only then when the target file name doesn't exist.
This reminds me of programming in assembly 40 years back. Everything is atomic, everything is done in its most elementary form. For the life of me I don't understand why Microsoft hasn't fleshed this out with additional functions. It seems designed to force us hourly workers to bill more hours to our customers. Sure am glad I'm paid by the hour for this work. My old system made functions like this super-easy, perhaps half a dozen lines of code.
Here, you have to use for each for sure and then use condition inside it as below design:
Current item is the blob which you want to work with. Here, i have used http trigger, you can use recurrence in place of it. Alternatively, Inside for each you can set the blob to a variable and then you can process that variable outside of it also.
Output:If blob name matches:
If it does not match: