


Here is the scenario:
we are using Azure Synapse analytics with 100 DTU, we have several tables.
All tables are round robin distributed and clustered columnstore because data is loaded once in a day and we want it to be quick.
All these tables are big having 50+ columns and millions of records (around 30m)
There is one load_table table which contains information about last load of all the tables.
SQL Query1:
SELECT load_time FROM load_table WHERE table = 't2';
when I execute this query on table, this gives me one timestamp as output for that table. format is like this "YYYY-MM-DD TT". This query normally runs fine within 5-10 secs.
SQL Query2:
SELECT top 100 * FROM t2;
t2 is big fact table containing millions of records having 50+ cols. When I run this query it takes 2-3 mins.
Problem occurs when I join these two tables and it takes 2-3 hrs to execute.
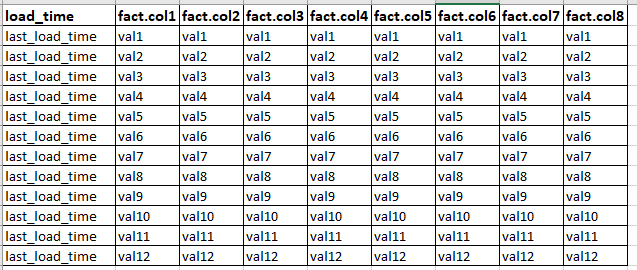
I want the result like loadtime as first column and all columns from second fact table.
joining is like below
SELECT t1.load_time, t2.* FROM
(SELECT load_time FROM load_table WHERE table = 't2') as t1 INNER JOIN t2
on 1 = 1;
Output look like below.
How can I achieve this result another way?
I am expecting below results
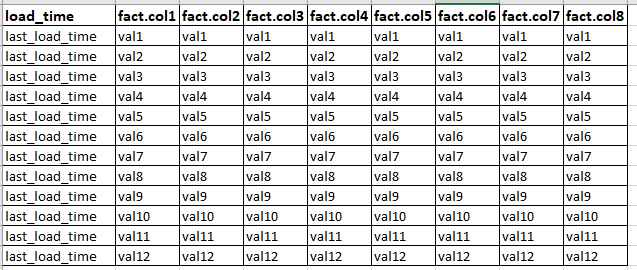
I have checked statistics of fact table those are updated
I have checked skew and it is fine
2
Answers
your join-condition is a bit…special.
If your load_table only returns one value per table (‘t2’), then you can just try this:
and if you use a stored procedure, you can first save the value to a variable:
when it return only one row and one column then why not take this in variable.
Declare @load_time datetime
SELECT @load_time=load_time FROM load_table WHERE table = ‘t2’;
Now,
SELECT @load_time as load_time, t2.* FROM t2 (NOLOCK)
i) DO not use
*and mention all the column name which you need in your output.ii) Use
nolockonly when there is no chance ofREAD UNCommittedor it do not matter.iii) Why you will use million of data,why not limit your resultset by using Pagination or
topclause.iv) Of course , we need at a minimum: the table and index definition for further investigation.also share your real query
if you simply use
which has millions of rows it will always take time.
Also,
select top 100 * from t2will also take time because it is without order by clause,sql optimizer is not sure to order on which column to get those 100 rows.So you have to share table scheme along with data type.Also if there is any index on table or unique key define.
Then accordingly we can do Paging to get only selected rows.