


I’m attempting to implement SCD2 within Azure Data Factory, but I’m encountering issues with the update mechanism. Instead of updating rows, my process seems to insert all rows from the source data into the destination, leading to duplicates.
This example is just trying to do the update, I scaled it down for simplicity – and I am using AdventureWorksLT2019 database.
Here’s a breakdown of the data flow:
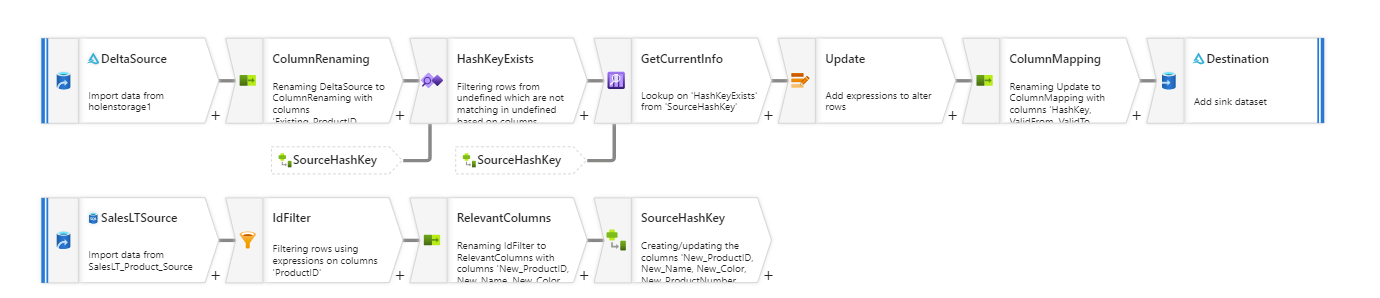
-
Data Retrieval:
- Source Data: Retrieve the latest dataset from the source.
- Destination Data: Fetch the current dataset from the destination.
-
Hash Key Generation for New Data:
- For each new data record, generate a hash key using SHA2-256 based on the following fields:
New_ProductID,New_Name,New_ProductNumber,New_Color, andNew_StandardCost.
- For each new data record, generate a hash key using SHA2-256 based on the following fields:
-
Existence Check:
- Ensure that the generated hash key for new data doesn’t already exist in the destination dataset.
-
Data Lookup:
- Perform a lookup on the destination dataset. The criteria for this lookup is
Existing_ProductID == New_ProductIDANDExisting_Hashkey != HashKey.
- Perform a lookup on the destination dataset. The criteria for this lookup is
-
Row Alteration:
- Use an "Alter Row" operation with the "update if" condition set to always true (
true()).
- Use an "Alter Row" operation with the "update if" condition set to always true (
-
Column Selection and Renaming:
- Choose all columns prefixed with
NEW_from the source dataset. For the hash key, retain the existing one from the destination dataset.
- Choose all columns prefixed with
-
Data Sink (Inline – Delta Dataset Type):
- Settings:
- Table Action: None
- Allow Update: Yes
- List Of Columns Key:
Hashkey
- Settings:
Despite following the above steps, I’m still getting duplicate rows in the destination. I’ve tried various adjustments, such as changing the list of columns key and filtering before the sink operation (e.g., only inserting rows with ID = 707). However, these attempts haven’t resolved the issue.
I have no idea how to fix this. Any tips or help is appreciated!
2
Answers
Okay. So, turn out I was asking for a solution for apples when my problem was pears. It took me quite some time to find the root of the problem.
I was reading my data via Azure Synapse. I thought I should read the data with .parquet format in Azure Synapse. But, since I wasn't writing my data via an Azure Gen storage account gen2 (parquet) destination. So i wasn't actually using the parquet format. Reading through the format ".parquet" was actually wrong. Since I was writing the data via the DELTA format, I needed to use the file format "delta" to read the correct the data. Delta format - Microsoft
So when reading the data via the correct format, I got the correct view.
The reason reading through the .parquet format was giving me "duplicates", is that when writing through delta, it writes new files, and sets the old files as "Not Active", or "Do not use". Which the parquet reading form ignores, while the delta format takes this metadata in consideration. So, even though Delta datatype writes to parquet format, it's different from regular parquet files.
In sink settings, give the key column as
Product_id, instead ofhash key.When
hash keyis given as key column, rows will be updated based on thehash key. Since there are no matching columns onhash key, I think all rows are inserted and it results in duplicate rows.When the key column is given as
product_id, all rows for the matching product ids will be updated with new values.