 Question posted in
Question posted in 

I know how to read a file in the Azure Data Lake Storage, but I don’t know how to read a file that is listed under the Integration Dataset section in Azure.
I know how to read a file in the Azure Data Lake Storage, but I don’t know how to read a file that is listed under the Integration Dataset section in Azure.
2
Answers
An integration dataset acts as a blueprint for your data, helping you specify its structure and whereabouts in a data store.
It is a guide that is used in your data pipelines and data flows how to interact with your stored information.
A CSV file with customer data in Azure Blob Storage.
You create an integration dataset to define details like the file’s structure (such as column names and data types) and its location in Blob Storage.
Later on, you can use this dataset within Synapse pipeline activities or data flows to read from or write to the CSV file.
An integration dataset does the heavy lifting of telling your systems "what" your data looks like and "where" to find it in a data store.
If you want to Read data from your Spark notebooks
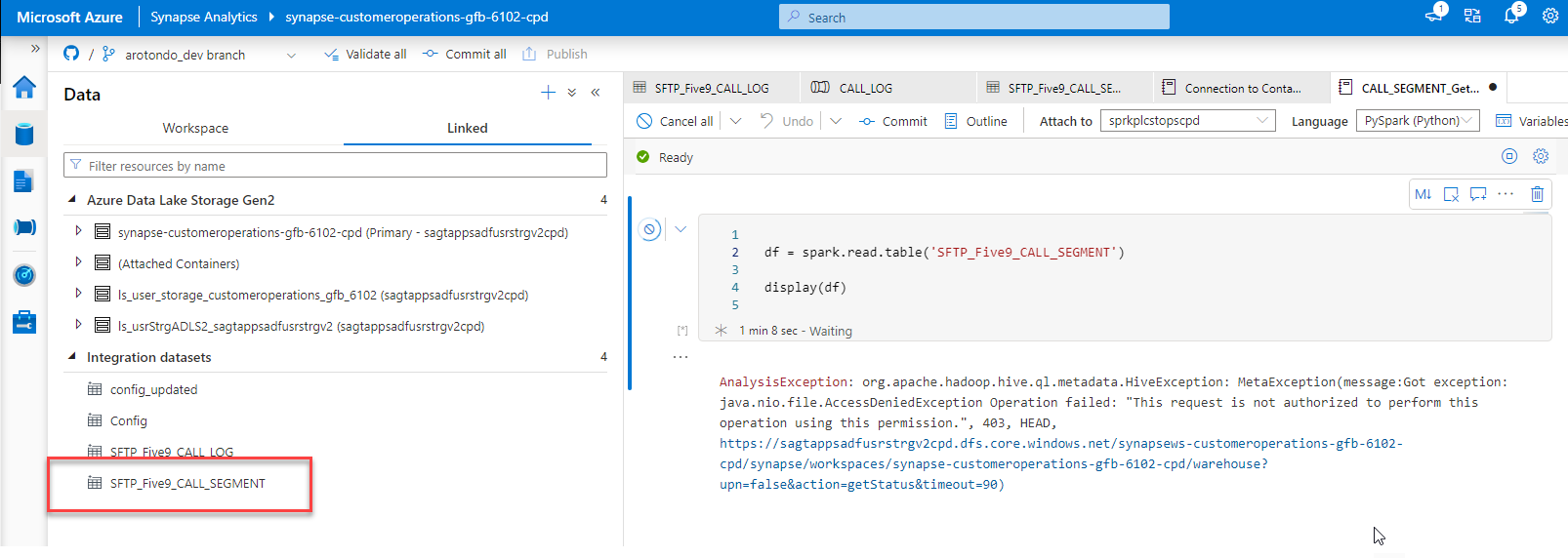
I have tried the below approach:
Results:
The integration dataset is not holding csv data. The delimited text dataset SFTP_Five9_CALL_SEGMENT is most likely pointing to a file in your data lake. In the connection blade, look at the File path’s [container]/[directory]/[file name] values. That file path is the information Spark needs to read the data.
In a notebook you can establish your filepath using abfss (Azure blob file system secure). To read this data into a dataframe set the filepath and read the data in using spark.read.csv.
Then create the dataframe using spark.read.csv()
Make sure you format abfss properly
The container name is to the left of the @ symbol. **Do not include it to the right of the @ symbol. Only include the directories you need to descend through after the container.
abfss://[email protected]/< directories within container to the file >
In DileeprajnarayanThumula’s example, they are using a file path leading directly to the delimited file in the data lake:
abfss://[email protected]/jan19.csv
You could also have a folder within the container say one for the month of January (jan). The path would then be ‘abfss://[email protected]/jan/jan19th.csv’
You could read all the files in a given directory into one dataframe: