


I am currently building a Python script that takes the price of trainers from the Nike website and pushes the price into a CSV file. Originally, the code took the element where the price data lives but after it failed, I switched to using CSS selectors, since Nike’s prices for its products are wrapped in CSS. But when I ran the script, it couldn’t extract the price data. I was stumped, so I modified the script to account for elements that are dynamically loaded in Javascript after the initial page load. But after all of that, I still can’t get it to push the price and the product into the CSV file. I deciced to modifiy the code to extract the code using xPath. However all of that I still couldn’t extract the price data and push it through the CSV file.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import numpy as np
import pandas as pd
# Get the website using the Chrome web driver
browser = webdriver.Chrome()
# Create an empty DataFrame to store the results
df = pd.DataFrame(columns=["Product", "Price"])
# Define a list of websites to scrape
websites = [
'https://www.nike.com/gb/t/dunk-low-retro-shoe-Kd1wZr/DD1391-103',
'https://www.nike.com/gb/t/dunk-low-retro-shoe-QgD9Gv/DD1391-100',
'https://www.nike.com/gb/t/dunk-low-retro-shoes-p6gmkm/DV0833-400'
]
# Loop through the websites
for website in websites:
browser.get(website)
try:
# Attempt to find the price element by its xPath
price = WebDriverWait(browser, 20).until(EC.presence_of_element_located((By.XPATH, '//*[@id="PDP"]/div[2]/div/div[4]/div[1]/div/div[2]/div/div/div/div/div')))
# If found, extract the text and add to the DataFrame
df = df.append({"Product": website, "Price": price.text}, ignore_index=True)
print("Price for", website, ":", price.text)
except:
# If the element is not found, print an error message
print("Price not found for", website)
# Close the browser
browser.quit()
# Save data frame data into an Excel CSV file
df.to_csv(r'PriceList.csv', index=False)
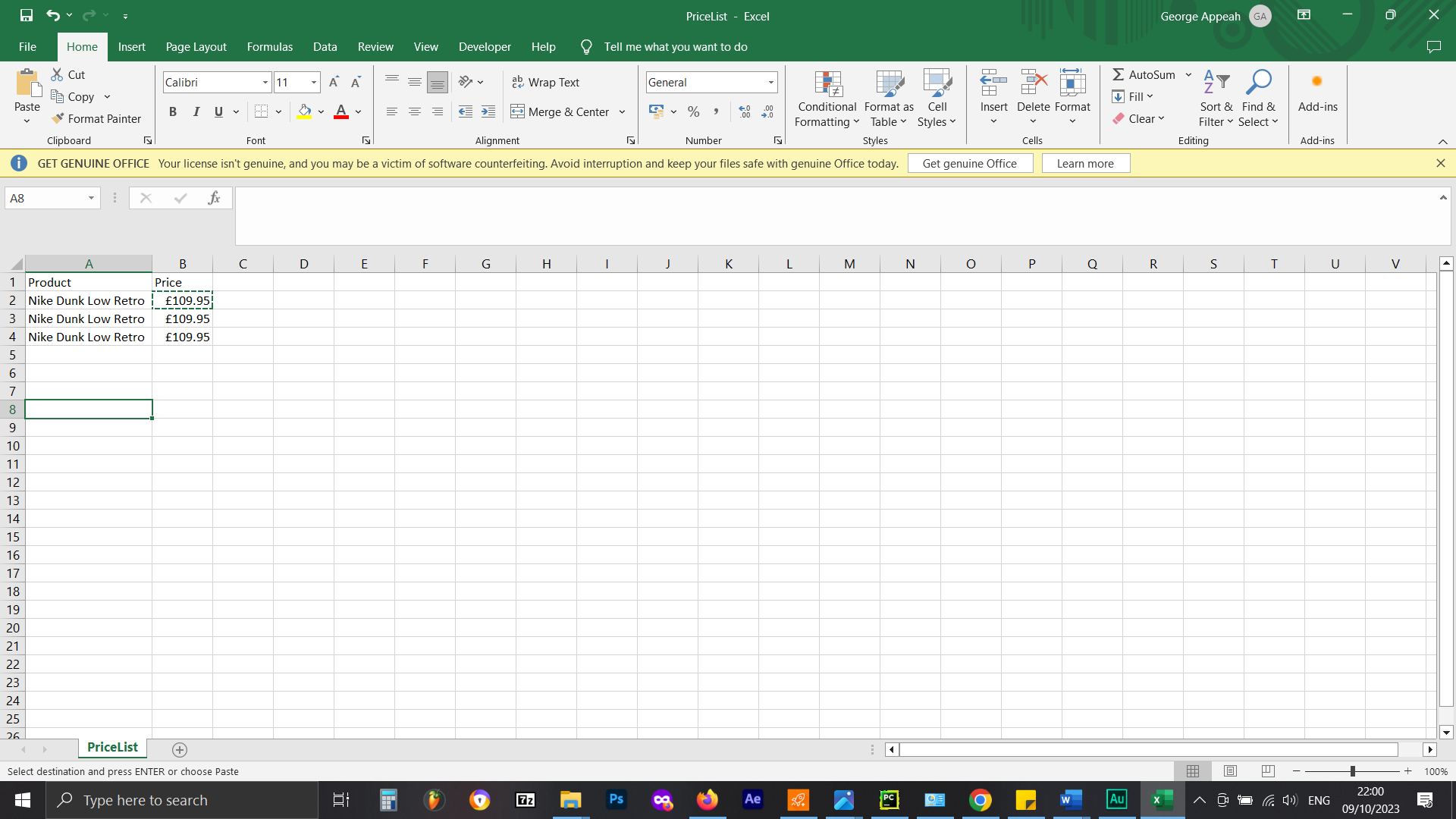
The code is suppose to take the element where the price data lives and push into a CSV file
A visual aid of what the code shoudl do
{kind=link}
2
Answers
appendwas removed from pandas.Instead you can use
_append.For some reason,
textdoesn’t seem to work (on my computer).Instead, you can use the
get_attribute("innerHTML")Here is the final code.
This answer is only ment to get a better XPath. I don’t know if that is the cause of your problem.
I would use a
@id-attribute that is closer to your target. Which is this one:@id='pdp_product_title'But it seems like there are somehow two html-blocks with the same h1/@id, which is not valid…but to overcome this you could use this explicit XPath:
An simpler XPath version would be this one:
The
[1]predicats are just to tell the XPath engine not to look any further than the first one. Could be a little performance-advantage.