


My current database approach looks like this:
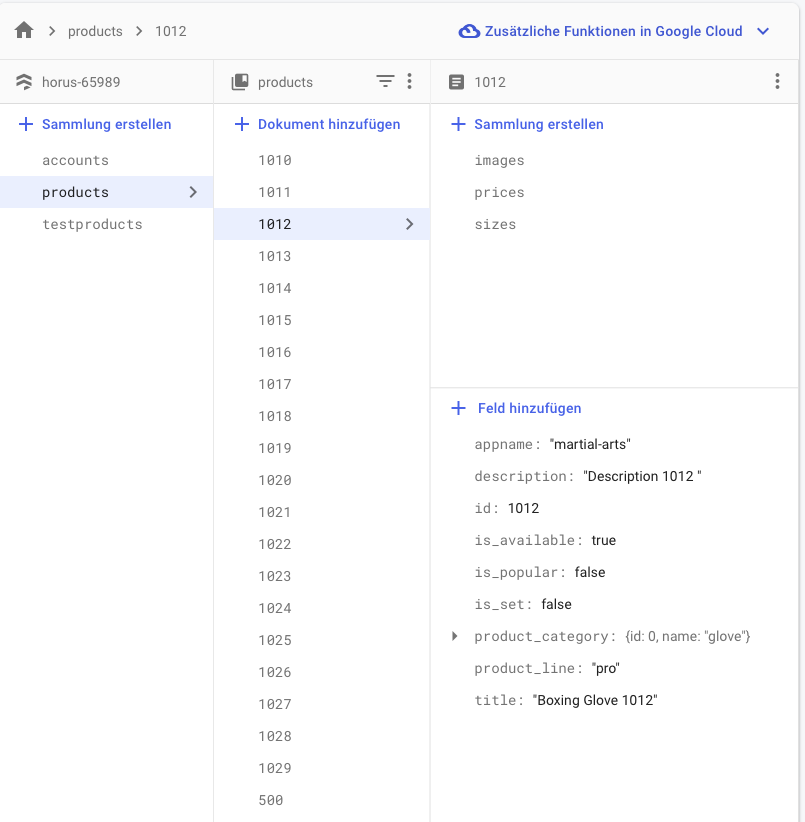
Now when I stream products, I want for every product the subcollections (images, prices, sizes).
What will be the best idea to fetch this in a stream, without using a lot of reads? I heard of something like a collection group.
Or should I just store every subcollection in the main collection?
2
Answers
How collection group query work just read all documents with same collection name, So if you run a collection group query without
.where .limit etcfor images, You will read all documents in every images collection.In this case you have different collection name, So you will need 4 listener,
products, images(Collection group), prices(Collection group), sizes(Collection group),then put associated data together on client.It’s not easy to say which approach is better, Firestore charge per document, If you want to minimize cost of reads, Maybe it make sense, But notice that the maximum size for a document is 1MB, Also if you use
.getin rules also charges.As @DougStevenson mentioned in his comment, there is no way in which you can change the way Firestore is billing us. You’ll always have to pay a read operation for each document you get. If the images, prices, and sizes are not too large, then you can add all that information inside the product document. This means that you’ll don’t have to perform additional reads to get that data. You’ll always have that data available inside the product document (object). This technique will work only as long as the details of the product will stay below the maximum limitation of 1 Mib.
Another optimization in your case might be to add all the products that correspond to a category in a single document. That will also work only as long as you stay below the maximum limit.
Another important thing would be to use pagination when you read multiple documents. This means that you have to load the data in smaller chunks. This technique will reduce the number of reads you perform.
A collection group query will only help if you need to read documents from multiple collections or subcollections that have the same name. However, this feature will not reduce the number of reads. The billing is the same also in this case.