


I am trying to parse through and extract data from HTML using Python and Beautifulsoup.
The sample HTML looks like this (it has multiple such structures being repeated:
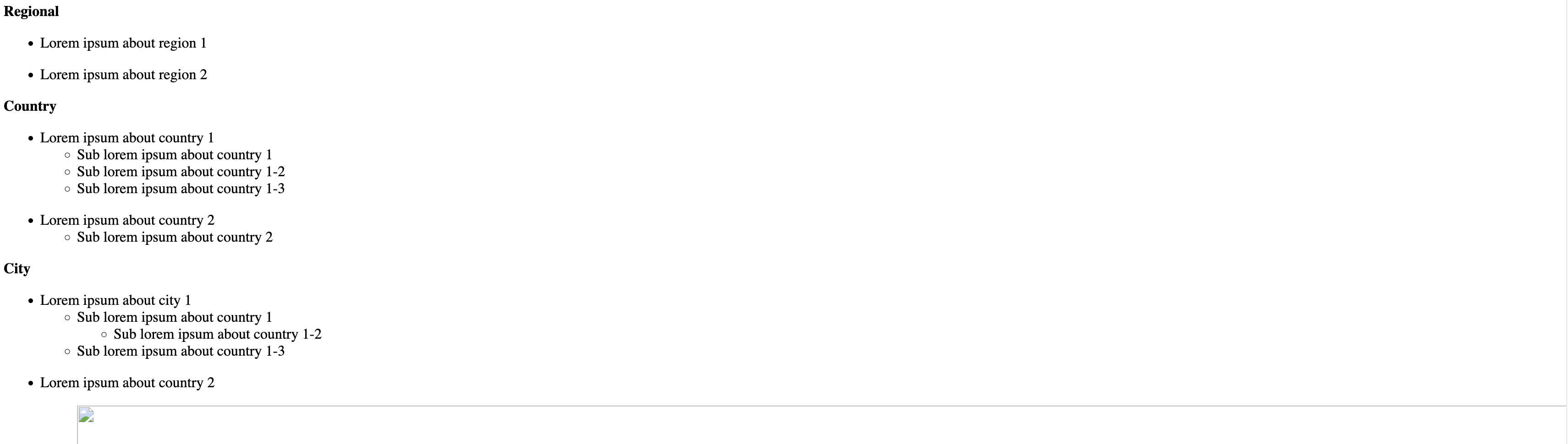
Here is a sample code snippet that generated the above screenshot:
<div class="indented"><p id="1" class="">
<strong><strong><strong><strong><strong><strong><strong><strong><strong><strong>Regional</strong></strong></strong></strong></strong></strong></strong></strong></strong></strong>
</p>
<ul id="2" class="bulleted-list">
<li style="list-style-type:disc">Lorem ipsum about region 1
</li>
</ul>
<ul id="3" class="bulleted-list">
<li style="list-style-type:disc">Lorem ipsum about region 2</li>
</ul>
<p id="4" class="">
<strong><strong><strong><strong><strong><strong><strong><strong><strong>Country</strong></strong></strong></strong></strong></strong></strong></strong></strong>
</p>
<ul id="5" class="bulleted-list">
<li style="list-style-type:disc">Lorem ipsum about country 1
<ul id="ac" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 1
</li>
</ul>
<ul id="ad" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 1-2</li>
</ul>
<ul id="ae" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 1-3</li>
</ul>
</li>
</ul>
<ul id="6" class="bulleted-list">
<li style="list-style-type:disc">Lorem ipsum about country 2
<ul id="ab" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 2
</li>
</ul>
</li>
</ul>
<p id="7" class=""><strong><strong><strong><strong><strong>City</strong></strong></strong></strong></strong></p>
<ul id="8" class="bulleted-list">
<li style="list-style-type:disc">Lorem ipsum about city 1</li>
<ul id="acc" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 1
<ul id="add" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 1-2</li>
</ul>
</li>
</ul>
<ul id="aee" class="bulleted-list">
<li style="list-style-type:circle">Sub lorem ipsum about country 1-3</li>
</ul>
</ul>
<ul id="9" class="bulleted-list">
<li style="list-style-type:disc">Lorem ipsum about country 2
<figure id="a" class="image"><a
href="a.png"><img
style="width:3040px"
src="a.png"></a>
</figure>
</li>
</ul>
</div>
And here is a sample of how the above appears in Chrome’s console:
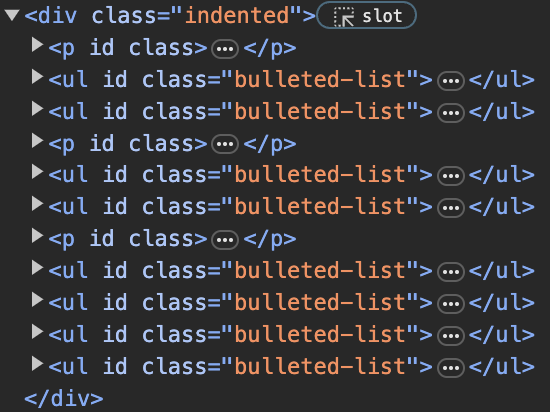
My objective is to get all the nested text under the City <p> tag. You can assume that the City <p> tag will always be the last <p> tag before the <div> it sits in is closed out. Under the City <p> tag, bullet points can have multiple layers of nesting and may have text in different formats (eg: bolded, italicized and so on). Any non-text data like images should be ignored.
Given the HTML structure seen in the Chrome console above, unfortunately the <ul> elements are not direct children of the <p> tag, which is making it difficult for me to accomplish this task.
Anyone have advice on how I can do this programmatically? Thanks
2
Answers
IIUC, you can use
tag.find_previousto check if the tag you’re in is underCityor not. E.g.:Prints:
EDIT:
Prints:
The HTML is invalid which makes working with standard tools more difficult than it needs to be. See the HTML validator.
Your
<p>elements should include the unordered lists and not end immediately after your opening<p>. Nested unordered lists must be done properly (inside a list item, not as a direct child of another unordered list.In terms of selecting the last
<p>child of some<div>elements, or any elements whatsoever, this is what CSS selectors do. A web developer would simply use JavaScript’s.querySelectorthen get the.textContent.Any other tool for this job is the wrong tool.