


I’m trying to write a bot that sends an email when there is a warning from the German Weather Service (Deutsche Wetterdienst DWD). This bot will be implemented in Python on my Raspberry Pi.
I want to extract some information from the DWD Website for, let’s say, Berlin. The URL could be
https://www.dwd.de/DE/wetter/warnungen_gemeinden/warnWetter_node.html?ort=Berlin-Mitte
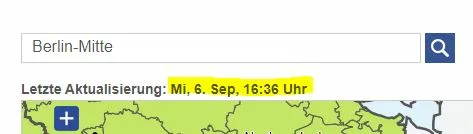
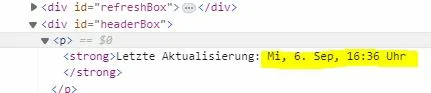
First I want to extract the latest timestamp (https://phpout.com/wp-content/uploads/2023/09/Ge224-jpg.webp). When I examine the HTML information of this page, I find the corresponding id="HeaderBox" with the required timestamp (https://phpout.com/wp-content/uploads/2023/09/spMQm-jpg.webp).
{kind=link}
{kind=link}
Unfortunately, this date and time isn’t given when I pull the HTML code with Python. So here’s my code:
import requests
from bs4 import BeautifulSoup
url = "https://www.dwd.de/DE/wetter/warnungen_gemeinden/warnWetter_node.html?ort=Berlin-Mitte"
r = requests.get(url)
doc = BeautifulSoup(r.text, "html.parser")
doctext = doc.get_text()
print(doctext)
The result is always just "Letzte Aktualisierung: " and an "empty" line, even when I try last_date = doc.find(id="headerBox").
I am using the PyCharm IDE (community edition) and Python 3.11.
Any hints or ideas where to look are appreciated.
Best regards,
Christian
3
Answers
Thank you very much for your reply, it helped a lot. I got the solution close to your what you suggested. I installed chromium from the command line
sudo apt-get install chromium-chromedriverand added the executable to the PATH environment as shown in 1.Since Selenium has been updated, the arguments have changed a bit, as explained in 2.
The full code is now
The issue you’re encountering might be related to the way the page is loaded or structured. Some websites use JavaScript to load dynamic content, and when you use requests to fetch the HTML content, you might not get the dynamically generated content.
To extract information from websites with dynamic content, you can use a headless browser automation tool like Selenium, which can interact with the webpage and retrieve the content after it’s fully loaded. Here’s how you can modify your script to use Selenium to extract the timestamp:
First, you need to install Selenium. You can do this using pip:
Now, you can modify your script:
Make sure to replace /path/to/chromedriver with the actual path to the Chrome WebDriver executable on your Raspberry Pi.
This script will open the webpage in a headless browser, wait for it to load, find the element with the timestamp by its ID, and then extract and print the timestamp.
I think you could look at the requests sent to the server to fetch warnings.
When inspecting the network, I saw these GET request URLs:
The response was
The timestamp right there corresponds to the exact time of last update (as I checked) and does not change when the website is reloaded (unless the last update also change).
You can format it and check for yourself. Hope this helps. Cheers.