


I am new to BS and trying to scrape a results page and access all the results from it which are kept in a list. I am able to access the ordered list that contains all the results, but unsure of how to iterate through all of them and pull all the info I need.
Here is the html for the page im scraping: Page HTML
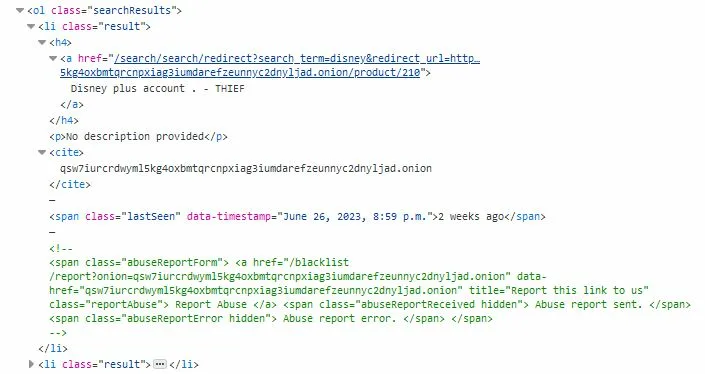{kind=link}
I am trying to grab the href title, href link, description, and data timestamp. The end result should be in a container that look like this:
{title: ['Disney plus account . - THIEF'], link: [/search/search/redirect?search_term=...], description: ['No description provided'], timestamp: ['June 26, 2023, 8:59 p.m.']}
Here is my code for accessing the list:
result = session.get(url)
soup = BeautifulSoup(result.text, 'html.parser')
ordered_list = soup.find_all('ol', class_ = 'searchResults')
Where should I go from here? How would I go about iterating and pulling info from each result? Any help is appreciated, thanks!
2
Answers
could you share the url with me so I can test it out?
This is the code for printing the results, with conditional checks for each value if it exists. You can use a list or DataFrame to store the results if you want to save them for later on.