


I need to exctract a list of Accession number.
I am a PhD student in biology working with GEOdatabase on NCBI website which give me datasets of genes.
Each dataset possesses an Accession number, generally starting by "GSE" followed by numbers.
I would like to exctract the list of Accession number present in the page after my research.
Here is a screen shot of what I would like to exctract (highlighted in yellow), from the page : https://www.ncbi.nlm.nih.gov/gds/?term=brain.
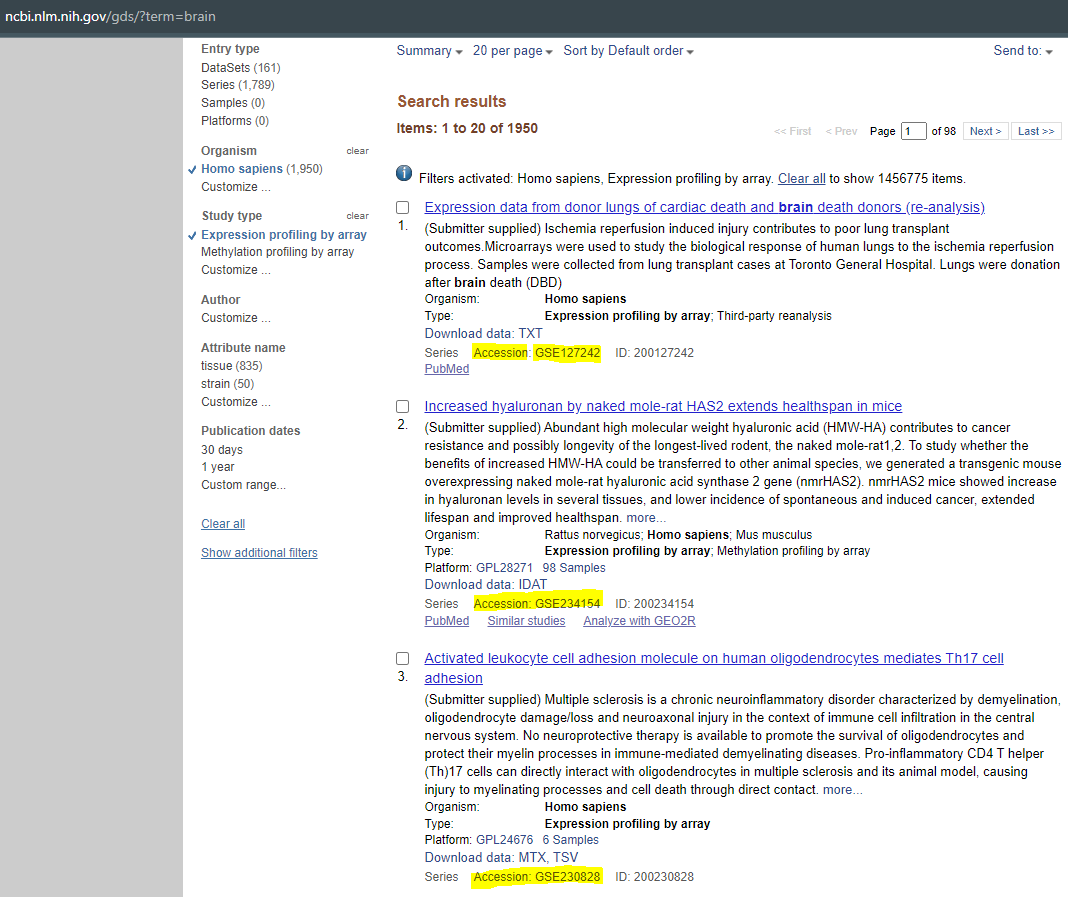
Is it possible to exctract it, writting a script via the console when I use inspect element ?
Or any other idea ?
Sorry if I don’t use correctly any of the previous term , I am not a dev.
Thank you for your help !
2
Answers
That’s rather easy. If we look up the HTML of that page, we can see that
Series Accession: ... ID: ...results are wrapped in<div>elements with a css classresc.To obtain those:
Looking further, the actual results are wrapped in a pair of
<dd>elements, where the first element holds the Accesion number.So it’s just going over all the
<div class="resc">elements and log the first child<dd>element’s text – which can be retrieved using the .innerText property.Executing the following line will output all the numbers to the console:
There is a scraping library named Beautifulsoup for this case https://www.crummy.com/software/BeautifulSoup/bs4/doc/
You can right clik and inspect the yellow marks and get the name of the class and build your python script.