


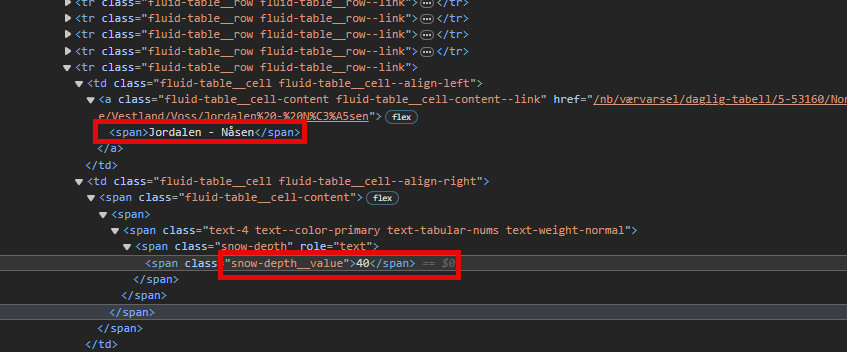
I want to extract a snow depth value from a weather site to a dataframe. (https://www.yr.no/nb/sn%C3%B8dybder/NO-46/Norge/Vestland) Specifically the snow depth for the Jordalen – Nåsen area.
Screen shot
{kind=link}
The closest I’ve gotten is printing all the values using this code:
import pandas as pd
import requests
from bs4 import BeautifulSoup
r=requests.get('https://www.yr.no/nb/sn%C3%B8dybder/NO-46/Norge/Vestland')
soup = BeautifulSoup(r.content, 'html.parser')
result=soup.find_all("span", {"class": "snow-depth__value"})
print(result)
But, i’ve been unsuccessful in figuring a way to transfer this specific value to a pandas dataframe.
2
Answers
This worked for me in bs4, I think the actual parameter in
find_allis calledclass_due toclassbeing special reserved word in python:The use of a
Generatorcomprehension here (by using()instead of[]) means that theint(span.text)will be lazily evaluated when pandas needs to actually iterate through the values while initializing the DF.You can write it to a
DataFramelike this:UPDATE:
I think it’s worth mentioning that this will flatten all of the snow depths in that table into a 1D structure when in reality they form sort of an
Nx32D array whereNis the number of rows.You can use the
stringvariable to find the inner content of a HTML node. See: hereLike this:
With this you have a list you can than write into a dataframe. See here