


I am very new to web scraping and want to scrape this website.
This is what I tried and didn’t know how to continue.
import requests
from bs4 import BeautifulSoup
url = "https://www.xbox.com/en-US/browse/games"
response = requests.get(url).text
soup = BeautifulSoup(response, 'lxml')
game_titles = soup.find('li')
I want the title, image url, genre and image url for each game. How do I do this?
Here is the html script.
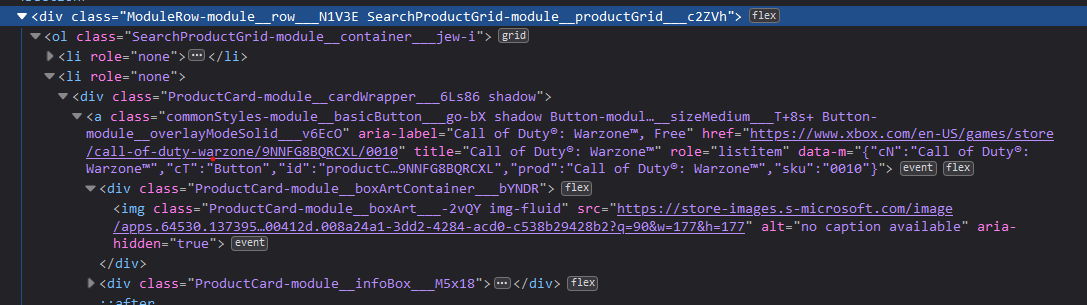
2
Answers
To get the info for each category, you need the class names. Looking at the site, here’s what I found.
Titles are
spans with the class name ofProductCard-module__singleLineTitle___32jUF typography-module__xdsBody2___RNdGY.Images are
imgs with the class name ofProductCard-module__boxArt___-2vQY img-fluid.Genres don’t seem to be listed.
Start off by initializing bs4.
Titles
Images
The
title_textsandimage_srcsarrays will give you what you’re looking for.The games-list is loaded via Javascript so
beautifulsoupdoesn’t see it. To load the game title list and image URLs you can try this example:Prints: