


Using BeautifulSoup/Python, I like to get the td text, Med from the following screenshot, or the ETF Risk from this website.
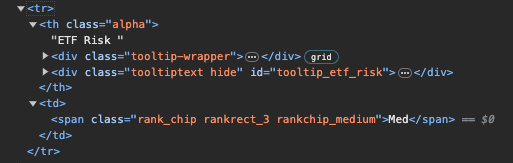
I tried the following code, but it didn’t work. What should be corrected?
Risk = soup.find('th', string="ETF Risk").find_sibling("td").text
2
Answers
In your code, you should use the method
find_next_sibling, here is the workable one.You could also use use
css selectorsandpseudo classlike:-soup-contains()to search by text values.But why not using HTML structure here – There are id attributes available:
Example