


I am trying to scrape the text from 5 different divs of a website, but the problem is that I cannot make use of the class name nor of the ID. I observed that what those divs have in common, is that the text of those 5 different divs are encapsulated in a span attribute, and that attribute is only used where I need to scrape the text from. This is my code so far, but I am stuck at the beginning of the scraping:
const fs = require("fs/promises");
const express = require ("express");
const cors = require("cors");
const _ = require("lodash"); //pick a random item from an array
const { v4: uuid } = require("uuid"); //object destructuring; uuid to generate unique id
const { sample } = require("lodash");
const cheerio = require("cheerio");
const axios = require("axios");
async function performScraping(){
const app = express();
app.use(express.json()); //support json
app.use(express.cors());
//Downloading the target web page
//by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://wsa-test.vercel.app/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
});
//parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data);
//initializing the data structures
//that will contain the scraped data
//scraping
const descriptions = document.getElementsByTagName("span");
for(desc of descriptions){
}
app.listen(3000, () => console.log("API Server is running..."));
}
So, tldr, what I really want to to is to extract the title of the article and the short description of it, using Cheerio, both being in a span attribute. I am also attaching an image of the HTML and the span in cause: HTML
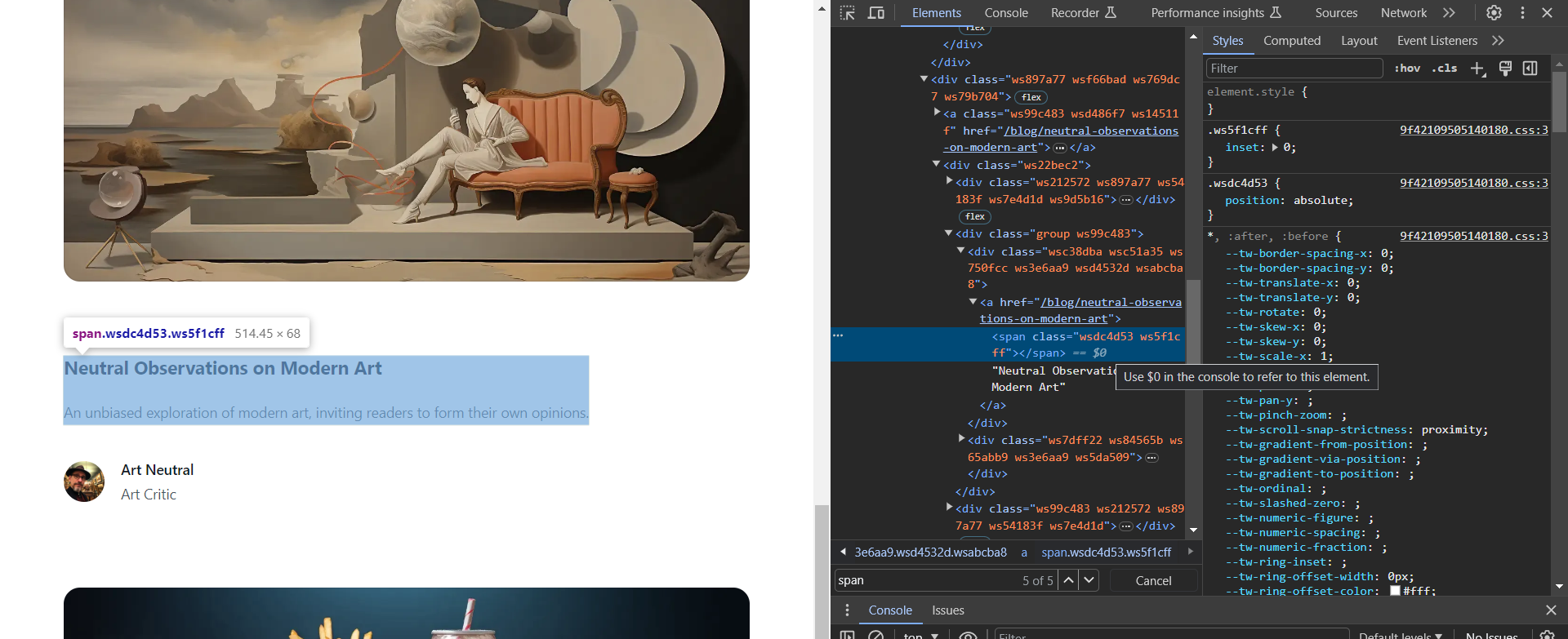{kind=link}
I tried to play with different DOM elements, but none worked.
UPDATE: Regarding my problem with the IDs and class names constraint, I was thinking of this solution, as a rule came to my mind. Any idea if it’s any good?
const links = $('a');
for(let i = 1; i < links.length; i += 2){
const title = $(links[i]).text().trim();
const shortDescription = $(links[i]).nextAll('div').eq(-2).text().trim();
if(title && shortDescription){
const scrapedData = {
title: title,
short_description: shortDescription
}
scraped.push(scrapedData);
}
}
2
Answers
You won’t be able to get that data with a direct request to the static HTML, because the data you want is loaded asynchronously by JS. Always check
view-source:in the browser or print the HTML axios gives you to ensure the data’s there. Don’t trust the dev tools, which shows elements loaded by JS after the page load.You could use a browser automation solution like Puppeteer to extract the data you want:
If you’re unable to use browser automation, the data is in https://wsa-test.vercel.app/_next/static/chunks/pages/index-f116d58692ffa69b.js, but that’s a generated build file with a dynamic hash, so you’d have to make two requests. First, request the index HTML, then extract this script tag’s source with Cheerio:
After you have the script source URL, you can request the JS file in a second request and parse the data structure starting with
h=[{id:1,title:"The Joys of Gardening" ...out of the response text with regex. Finally, you’d process the data structure to pull out only the information you need.This is probably too much work and carries its own reliability risks (script URLs and object structures can change), so I don’t recommend it unless speed is absolutely critical or you’re in an environment where Puppeteer is too heavy to run.
Here’s a proof of concept of what this might look like:
evalis also possible instead of JSON5 for parsing the JS object (not JSON!) string, but it’s incredibly risky running untrusted JS, so I don’t recommend this in production:Hopefully this exercise helps motivate Puppeteer as the first option.
it looks like you can do: