


I try to extract the content of the right side on this page:
https://portal.dnb.de/opac.htm?method=simpleSearch&cqlMode=true&query=idn%3D1173921214
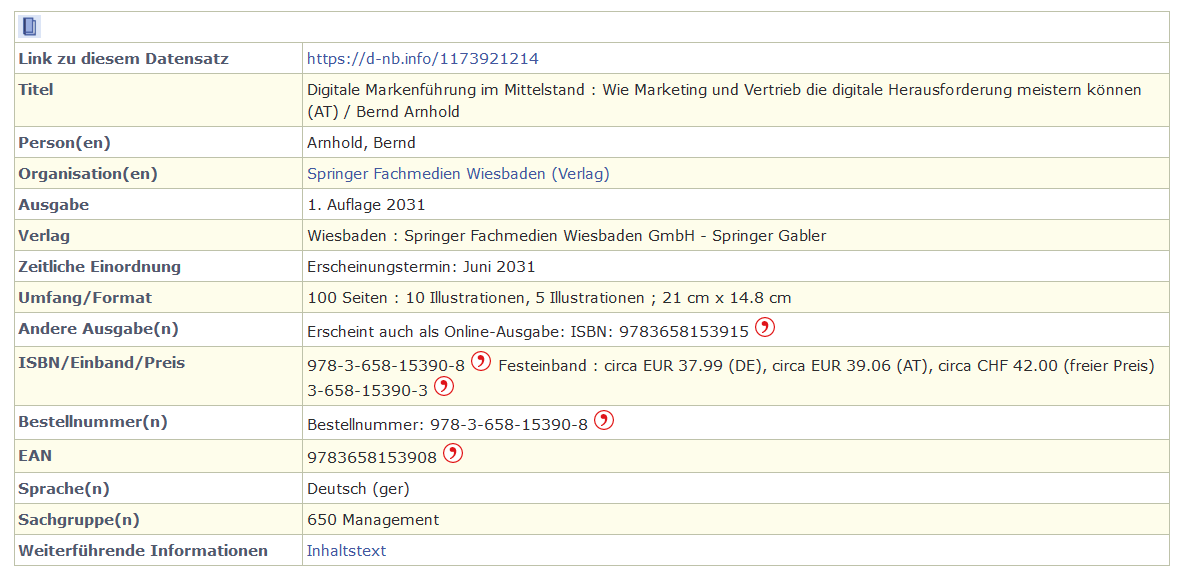
When we take a look on the html, the information is stored in this table:
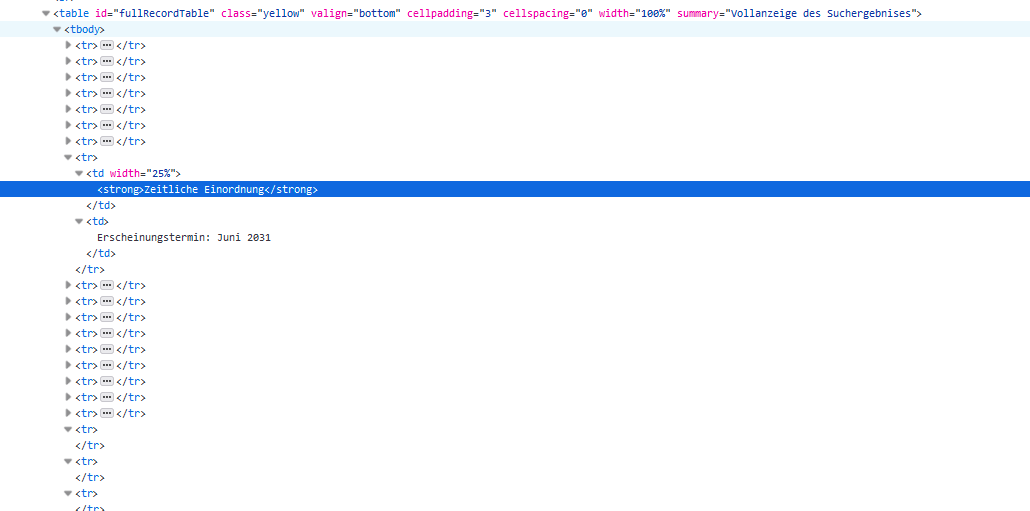
With my code snippet, I can´t reach the text I want to.
def getDescriptionDNB():
description = f'https://portal.dnb.de/opac.htm?method=simpleSearch&cqlMode=true&query=9783125466302'
response = requests.get(description)
soupedDescription = BeautifulSoup(response.content, "html.parser")
text = soupedDescription.find(class_="amount").text
if text == "Treffer 1 von 1":
autor = soupedDescription.find_all("tr")
for i in autor:
test = i.findNext("td").text
print(test)
The problem is, I don´t know how to get down to the inner <td> tag to get the information I want to.
Do you know, how I can solve this Problem?
2
Answers
Main issue is – HTML of page is broken, there are some
trwithouttdand without closing tag.Try to select your elements more specific or try to store info in
dictand pick by key.Create a
dictwithcss selectors:Create a
dictwithpandas.read_html():Output
Based on url of your snippet.
You need to break apart the key/value pairs as pointed out. Sticking with BeautifulSoup (your tool of choice) –
There are some other things. Improve on this yourself. Instead if selecting all the ‘tr’s in the document select the table, and then select the table:
and then move on to selecting the rows (‘tr’) in there.