 Question posted in
Question posted in 

I am working with the R programming language.
Suppose I take the answer from this stackoverflow post (from u/Michael Hardy): https://math.stackexchange.com/a/62963/1296713
Using R and the hyperlink (i.e. https://math.stackexchange.com/a/62963/1296713 ), I want to take this answer (only the answer, not the whole post) and save it as a PDF document (with the latex included) from R itself. I am also fine with a png image.
The final output should look like this:

I tried the following code:
# https://cran.r-project.org/web/packages/webshot/readme/README.html
library(webshot)
webshot("https://math.stackexchange.com/a/62963/1296713", "r2.png")
This code ran, but this is including the whole webpage – not just the answer from u/Michael Hardy:
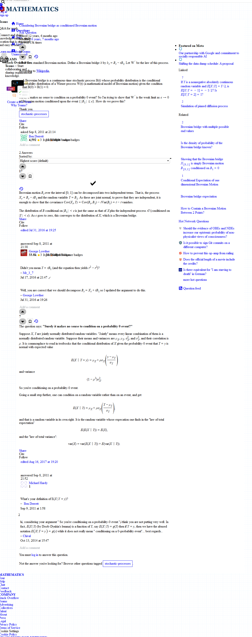
Can someone please show me how to do this correctly? Maybe this can be done more easily using rvest/httr webscraping?
Thanks!
- Note:
I also tried the following based on CSS selectors:
library(webshot)
url <- "https://math.stackexchange.com/a/62963/1296713"
selector <- ".s-prose.js-post-body"
webshot(url, "r2.png", selector = selector)
2
Answers
Using {chromote} to png:
The simplest but has some limittations is to exec the browser in headless mode for a PDF or a PNG.
Now a problem with headless is that, to add cookies or replies to a login prompt will need some JavaScript magic and that is why puppeteer is best option.
Anyway here is the output from the pure command line, we can easily trim off the top.

In this case I used Opera manually [* see comment below, as to why Opera in a case like this] but normally use Edge or Chrome headless. This alternative will pull the whole set of pages as editable PDF, then cut and paste the searchable contents.
Here just searching for Brownian, in the one page after trimming.

[*]
Opera uniquely, in manual mode, can
save as PDFa whole single HTML page, without page breaks. This makes it easier with PDF not to have to mess about with divisions. So you can edit/delete the unwanted content at will, with a good editor or PDF program).