


I wrote a code that converts a Word document to HTML using pypandoc because I even want images in that. The problem is my docx file contains characters ‘ and ’ which turn into something different in HTML when sent as a mail body. I want ‘ and ’ to be replaced with ', a normal apostrophe.
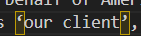
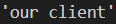
Check the attached images so that the difference is clear enough.
{kind=link}
{kind=link}
I tried a few ways as shown in the code below. I commented out ways which I tried but failed.
# Read the HTML file
with open(html_file, 'r') as file:
html_data = file.read()
# Replace all occurrences of ',' with '
# print("called")
html_data = re.sub("‘", "'", html_data)
html_data = re.sub("’", "'", html_data)
# html_data = re.sub(r'’', "'", html_data)
# html_data = re.sub(r'‘', "'", html_data)
# html_data = re.sub(r'“', '"', html_data)
# html_data = re.sub(r'”', '"', html_data)
# html_data = html_data.replace("‘", "'")
# html_data = html_data.replace("’", "'")
# html_data = html_data.replace('“', "'")
# html_data = html_data.replace("”", "'")
For example, my Word document contains a phrase i’d like to that should get converted to i'd like to.
2
Answers
I think you need to escape the character so it does not conflict with
stringdeclaration:Output:
Try this it works, in html ‘ is sometimes considered as ‘ and ’ is considered as ’ so it does not replaces using your code.