


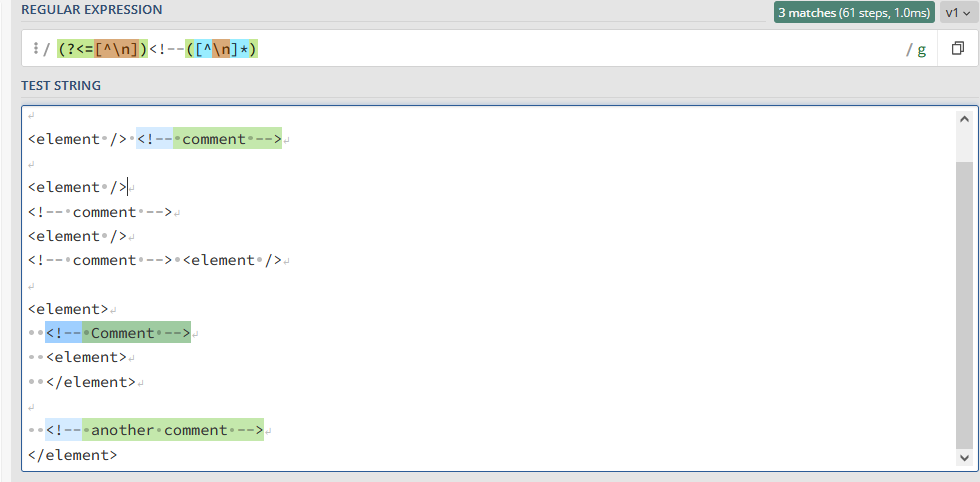
I tried using (?<=[^n])<!--([^n]*) currently it’s not capturing inline <!-- comment --> <element /> and for some reason also capture newline comment only. My current approach was to use lookbehind newline (n) and if it’s an inline comment erase it with empty space.
Test string:
<?xml version="1.0" encoding="utf-8" ?>
<element /> <!-- comment -->
<element />
<!-- comment -->
<element />
<!-- comment --> <element />
<element>
<!-- Comment -->
<element>
</element>
<!-- another comment -->
</element>
Is there something I’m missing? Or is there any better way?
PS: Have tried using parser and haven’t found any parser that differentiate between inline and newline comment.
2
Answers
Would this suffice:
(?:^[^Srn]*<!--(.*?)-->[^Srn]*<|>[^Srn]*<!--(.*?)-->[^Srn]*$)[^Srn]is anysthat isn’t a newline characterThe branch before
|covers inline comments before a tag (NB: that includes another comment!).The branch after
|covers inline comments after a tag (NB: that includes another comment!).The content of each match is contained either
match[1]ormatch[2].Use
.*?to match anything inside a comment and 2 possible version of inline comments combined: