


I’ve got the following jsonFile example that I’m trying to convert to a dataframe. I’ve looked through many examples on SO but all of them have a first level key in their json data. My data only has the value as the first level.
[
{
"product1": [
{
"start": 8,
"end": 9,
"part_number": "150-3333-900",
"description": "Description for 150-3333-900"
},
{
"start": 8,
"end": 9,
"part_number": "150-4444-900",
"description": "Description for 150-4444-900"
}
]
},
{
"product2": [
{
"start": 10,
"end": 11,
"part_number": "140-2222-800",
"description": "Description for 140-2222-800"
},
{
"start": 10,
"end": 11,
"part_number": "140-5555-800",
"description": "Description for 140-5555-800"
}
]
}
]I’ve tried the following and got a NotImplementedError. I thought this should work since I’m passing in a list of dictionaries.
import pandas as pd
import json
df = pd.json_normalize(jsonFile)
I tried the following and got some output but not in the format I’m looking for.
with open(jsonFile) as f:
data = json.load(f)
df = pd.DataFrame.from_dict(data)
display(df)
And I get this:

I also get the same output using this line of code:
df = pd.read_json(jsonFile, orient='records')
display(df)
What I’m looking for is this:
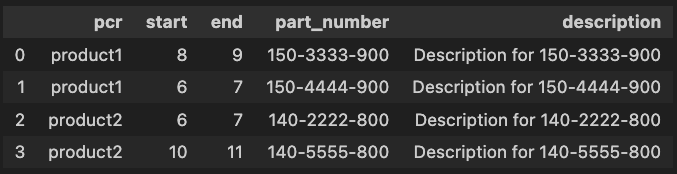
Can someone point me in the right direction? I tried transposing the output that I got above so my column headers would be the beginning of each row but I couldn’t get that to work either. Thank you.
2
Answers
You can achieve your desired result by iterating the dicts in your list, applying
json_normalizeto each one and appending the key as the product name:Output for your sample data:
Another possible option :
Output :