


I have the following JSON structure,
{
'total_numbers':1,
'data':[
{
'col3':'2',
'col4':[
{
'col5':'P',
'col6':'H'
}
],
'col7':'2023-06-19T09:29:28.786Z',
'col9':{
'col10':'TEST',
'col11':'[email protected]',
'col12':'True',
'col13':'999',
'col14':'9999'
},
'col15':'2023-07-10T04:46:43.003Z',
'col16':False,
'col17':[
{
'col18':'S',
'col19':'H'
}
],
'col20':True,
'col21':{
'col22':'sss',
'col23':'0.0.0.0',
'col24':'lll'
},
'col25':0,
'col26':{
'col27':{
'col28':'Other'
},
'col29':'Other',
'col30':'cccc'
},
'col31':{
'col32':[
{
'col33':'123456789',
'col34':'2023-07-14T02:52:20.166Z',
'col36':True,
'col38':{
'col40':[
{
'col41':'99999999999',
},
{
'col41':'34534543535',
}
]
},
'col55':'878787878'
},
{
'col47':'112233445566',
'col48':'2023-07-24T09:26:03.425Z',
'col50':True,
'col52':{
'col53':[
{
'col54':'99999999999',
}
]
},
'col55':'878787878'
}
]
}
}
]
}
Is there a dynamic function I could use to convert this structure to tabular form based on traversing through the JSON?
I came across this function (marked as solution) which i think could be helpful for my case. In the example I understand there will be 6 rows based on the number of levels in the json though I don’t understand the naming of some columns. The data is there but the column names are not correct a/c to its level. Is there any update I could make to the function to achieve this?
For example, the name of the columns should be actually root_data_col4_col5 and root_data_col4_col6
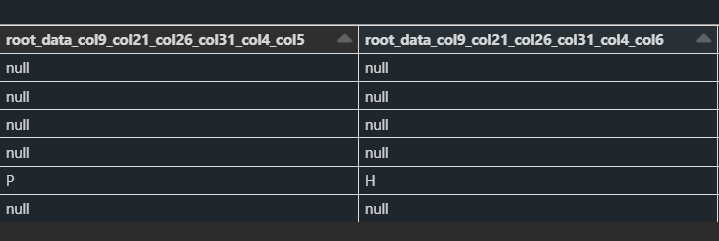
2
Answers
The following works in 2 steps:
firstly it breaks the JSON into alternating dicts and lists – removing all dictionaries containing dictionaries as top level values.
It then parses this new structure so that whenever there is a list (and hence the potential for duplicate keys) it creates a new row item for each element. Doing things this way results in 2 rows with data in them for ‘root_data_col31_col32_col55’ which I think is the intended behaviour.
I faced the same problem before and made a code that converts Json/Dict/List to a way that can be used in pandas dataframe.
when I saw your problem, I uploaded the code to github to make you able to clone it, also I got tons of ideas after I read @Andrew Louw code, so I uploaded the package to PYPI called JsonDF.
download the package via pip
or from GitHub
and I’ve no problem with contributions, so feel free to make anything.
that’s the code based on your problem
the output was like that :
output image