


I have the following code:
import requests
import pandas
api_url = "***"
Headers = { "Authorization" : "***" }
response = requests.get(api_url, headers=Headers)
obj = pandas.read_json(response.text, orient='values')
obj.to_csv('output1.csv')
And I get the follwing output in a CSV:
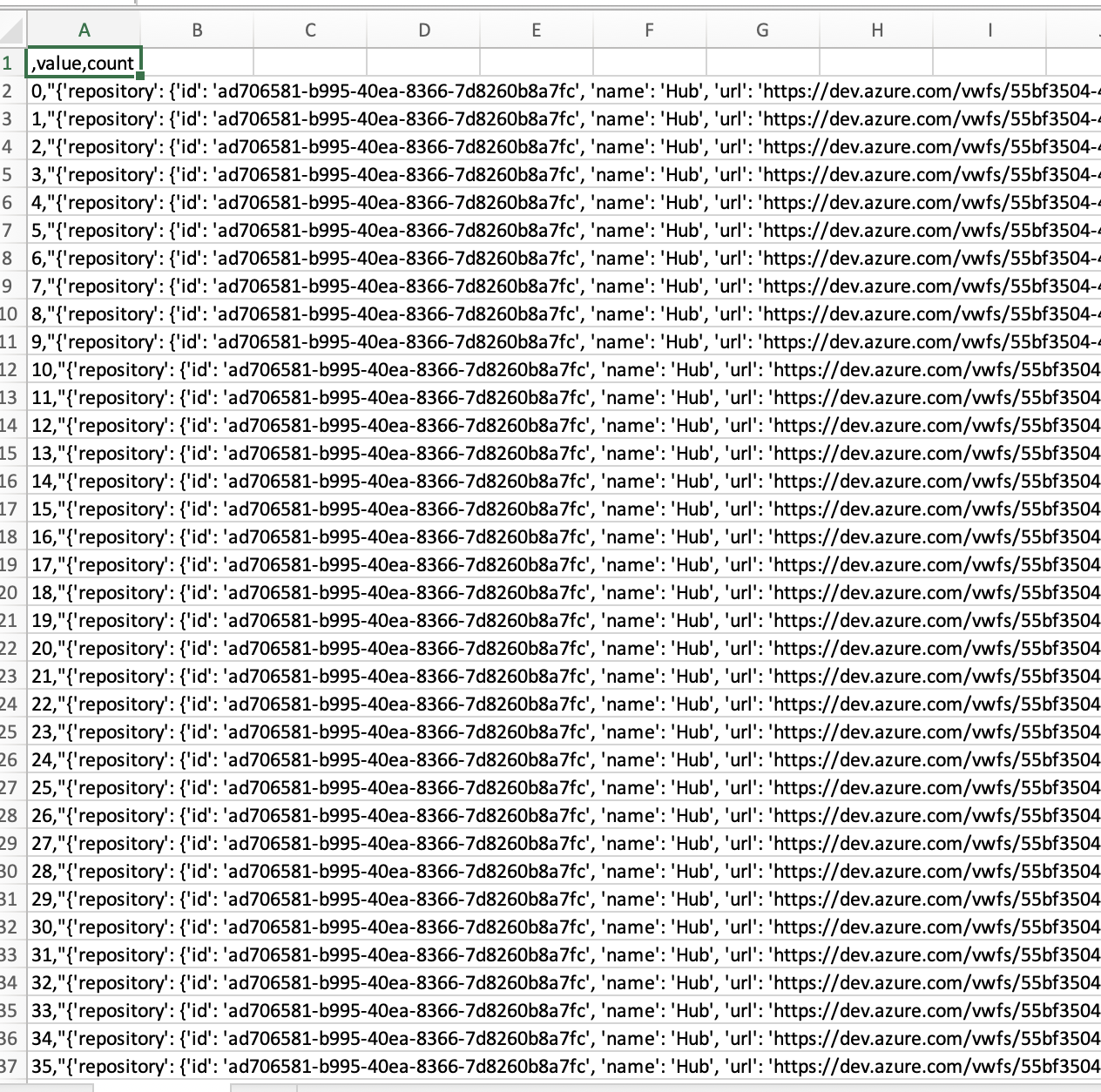{kind=link}
So the JSON-Keys are not the column names and everything is in Column A nothing in Column B and so on. How can I get the JSON-Keys as Column-Names?
df = pandas.json_normalize(response.json()["value"])
print(df)
looks like this:
pullRequestId codeReviewId ... completionOptions.transitionWorkItems labels
0 11885 11885 … NaN NaN
1 11965 11965 … NaN NaN
2 11958 11958 … NaN NaN
3 11936 11936 … NaN NaN
4 11923 11923 … NaN NaN
.. … … … … …
96 11220 11220 … NaN [{‘id’: ‘1d85b8f2-7712-46e6-9eb0-dd789ed3d7d1’…
97 11122 11122 … True NaN
98 11142 11142 … NaN [{‘id’: ‘1d85b8f2-7712-46e6-9eb0-dd789ed3d7d1’…
99 11194 11194 … True NaN
100 11201 11201 … NaN NaN
But the CSV looks like this with:
df.to_csv('output1.csv')
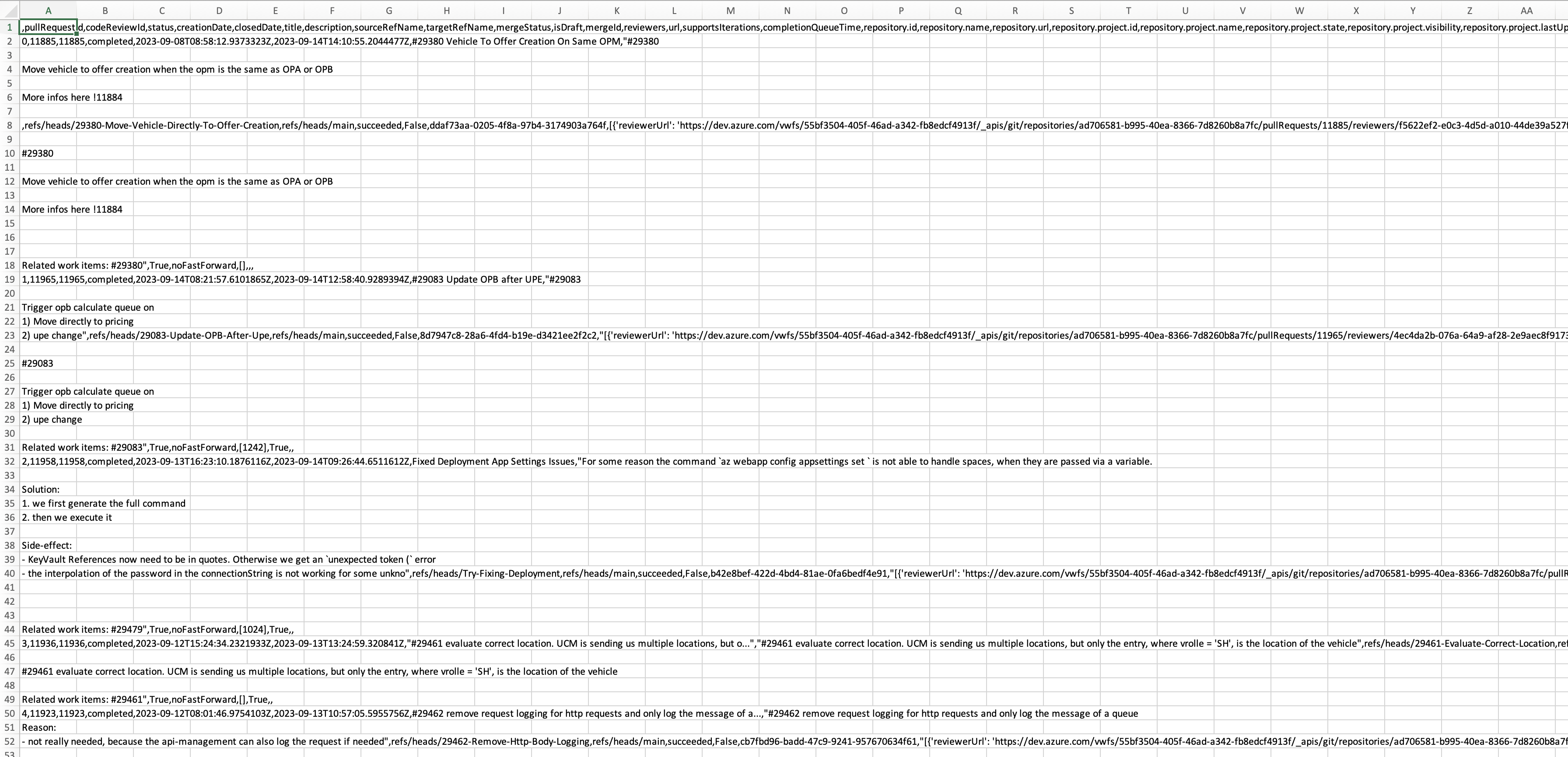{kind=link}
2
Answers
When importing JSON data into the Pandas DataFrame, you must set the orient parameter of pandas.read_json() correctly to use the keys in the JSON as column names. JSON data can be organized in different ways depending on how the data is structured. If you want to use your JSON data as column names, assume that your JSON data is structured as objects in a list. In this case, you need to set the orient parameter to "records". Here is an updated version of your code this way:
This script will convert your JSON data to "records", using the keys in JSON as column names. If your JSON data has a different structure or needs special handling, you can convert JSON data to DataFrame by setting the orient parameter appropriately.
Excel is known to have an awful support for CSV files. Long story made short, it generally can only load correctly CSV files that have been produced by Excel on the same system. Specifically the separator is given by the system locale.
Here, I would assume that you have a system (probably West European) that uses a semicolon (
;) as separator. The good news is that you can ask Pandas to use that separator with:If it still does not work, you will have to search in your system configuration which separator is expected, or alternatively build a minimal CSV file from your Excel system and read it in a text editor (notepad is enough) to see which separator is actually used.