


I am trying to use Google Gemini’s API in order to generate responses for a list of buildings in NYC. I have structured the prompt to give a format of a list of bullet points about building information. When writing the same prompt in the browser in Gemini, I am getting accurate information, but when writing prompts to test in postman the responses are inaccurate. I provided and explained my example below:
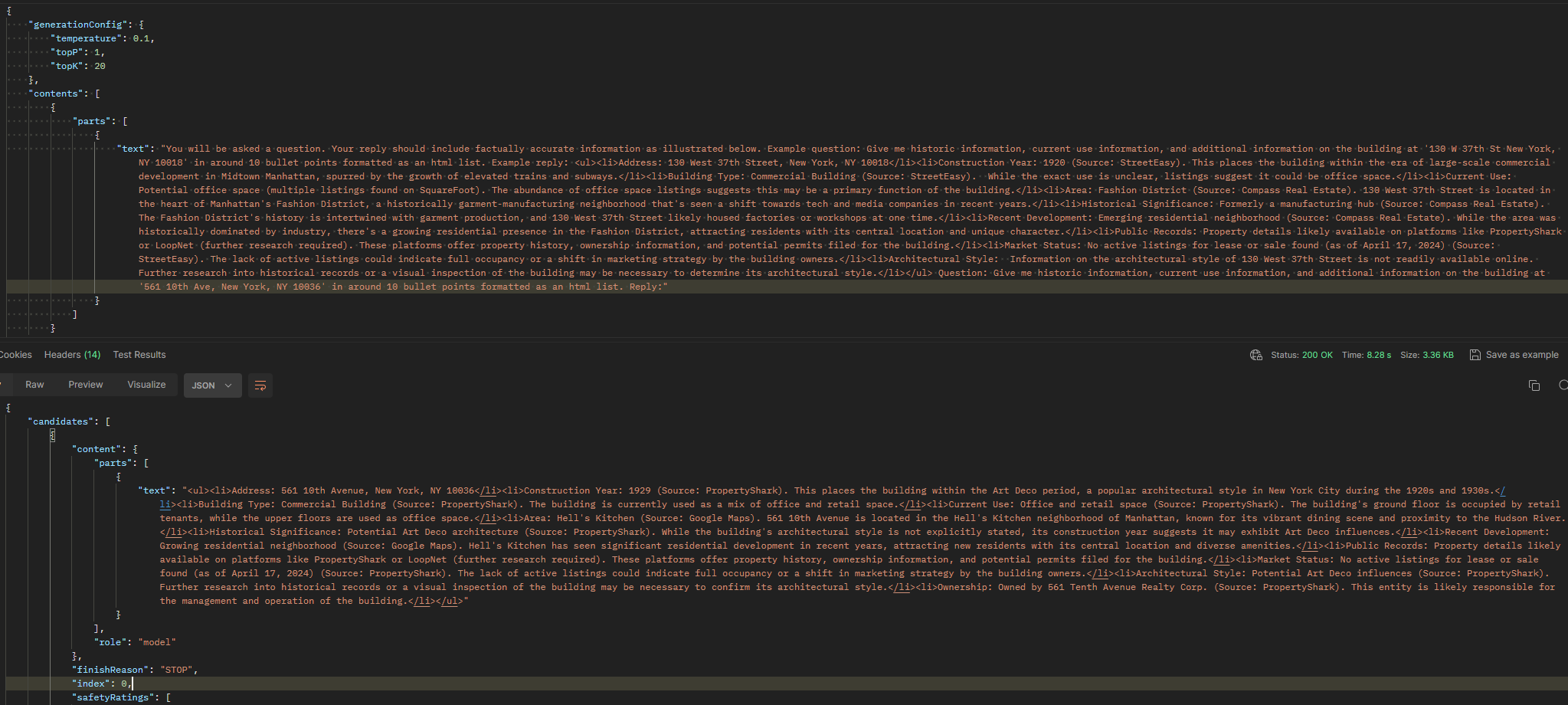
The address in the response was being constructed in 2001 not in 1929
{kind=link}
This issue here is that the building was built in 2001 finished in 2003 not in 1929. Other attempts to change the prompt give other years that are also in the early 1900s. Some of the other information in the response of the image above is also inaccurate, but my assumption is that if I can get one to work it will have them all work.
I’ve played with the generationConfig to no avail. What do I need to do in order to get pretty much the same response I would get on the browser as an output from the API call or what do I need to change in order to get the accurate information?
2
Answers
You can not. There is currently no way to get the exact same response from AI studio in the API.
If you are trying to get the same response from the Gemini web app then the response will be completely different in most cases. The Gemini chat app at gemini.google.com includes many models and sets of information, some of which are proprietary. It does not have an API.
Remember this is an ai not a database the response is generated real time and may change. It picks the most likely answer it can come up with at the time it is run.
The response generated by the LLM model is based on the data it has been trained on. It is important to note that Google Gemini web and API may have some differences in the micro model in their models named Gemini, leading to different answers. Even if both models are identical, they may still provide different responses because data is generated in real-time.
To obtain accurate data consistently, I recommend building an RAG pipeline and utilizing the LLM response from your data instead of the Gemini model data. However, it has its limitations and may not respond at all times. RAG still does not ensure 100% accuracy in the model.
In short, do whatever changes to get accurate information, but LLM will not guarantee to provide 100% accurate answers yet.