


I have below JSON string as a column in a pyspark dataframe.
{
"result":{
"version":"1.2",
"timeStamp":"2023-08-14 14:00:12",
"description":"",
"data":{
"DateTime_Received":"2023-08-14T14:01:10.4516457+01:00",
"DateTime_Actual":"2023-08-14T14:00:12",
"OtherInfo":null,
"main":[
{
"Status":0,
"ID":111,
"details":null
}
]
},
"tn":"aaa"
}
}
I want to explode the above one into multiple columns without hardcoding the schema.
I tried using schema_of_json to generate schema from the json string.
df_decoded = df_decoded.withColumn("json_column", F.when(F.col("value").isNotNull(), F.col("value")).otherwise("{}"))
# Infer the schema using schema_of_json
json_schema = df_decoded.select(F.schema_of_json(F.col("json_column"))).collect()[0][0]
df_decoded is my dataframe and value is my json string column name.
But it is giving me the below error –
AnalysisException: cannot resolve 'schema_of_json(json_column)' due to data type mismatch: The input json should be a foldable string expression and not null; however, got json_column.;
My expected output –
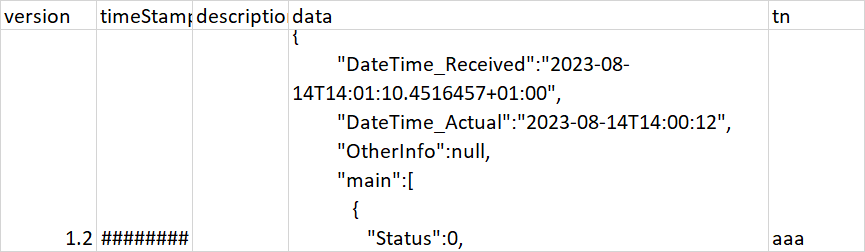
2
Answers
Does this start you on the way ?
I don’t have a real app to play with
.transpose()is the change.https://stackoverflow.com/a/77263073/22187484
This person has a complex answer for grouping and filtering that might help too.
Use sparks inference engine to get the schema of json column then cast the json column to struct then use select expression to explode the struct fields as columns