


I am trying to normalize a nested JSON file in pandas.
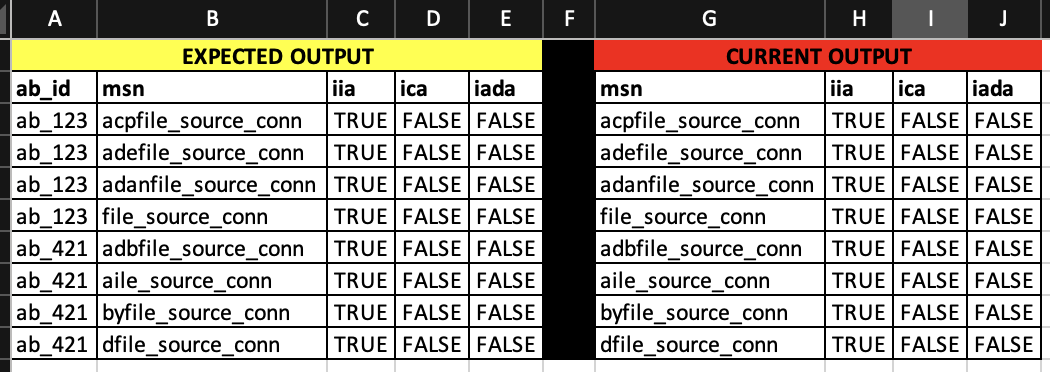
I am unable to get the ab_id column in the beginning as observed in the current output screenshot.
Additionally, since if I remove record prefix from my code, I am seeing an error and if I add it it generates a couple of columns which are empty.
The current and expected output is attached in the screenshot below:
Code used currently:
df=pd.json_normalize(data=response[‘val’],record_path=[‘activity’],meta=[‘msn’,’iis’,’ica’,’iada’],errors=’ignore’, record_prefix=’_’)
JSON file:
{
"id":"ijewiofn23441312223",
"val":[
{
"ab_id":"ab_123",
"activity":[
{
"msn":"acpfile_source_conn",
"iia":true,
"ica":false,
"iada":false
},
{
"msn":"adefile_source_conn",
"iia":true,
"ica":false,
"iada":false
}
}
]
},
{
"ab_id":"ab_421",
"activity":[
{
"msn":"adbfile_source_conn",
"iia":true,
"ica":true,
"iada":false
},
{
"msn":"aile_source_conn",
"iia":true,
"ica":false,
"iada":false
}
}
]
}
]
}
Can someone please help out?
Thanks so much in advance.
3
Answers
You can try to use
jsonmodule and construct the DataFrame manually:Prints:
Contents of
data.json:There is two extra
}in your json example. Also, this one doesn’t match the I/O images.But you can still try this :
Output :