


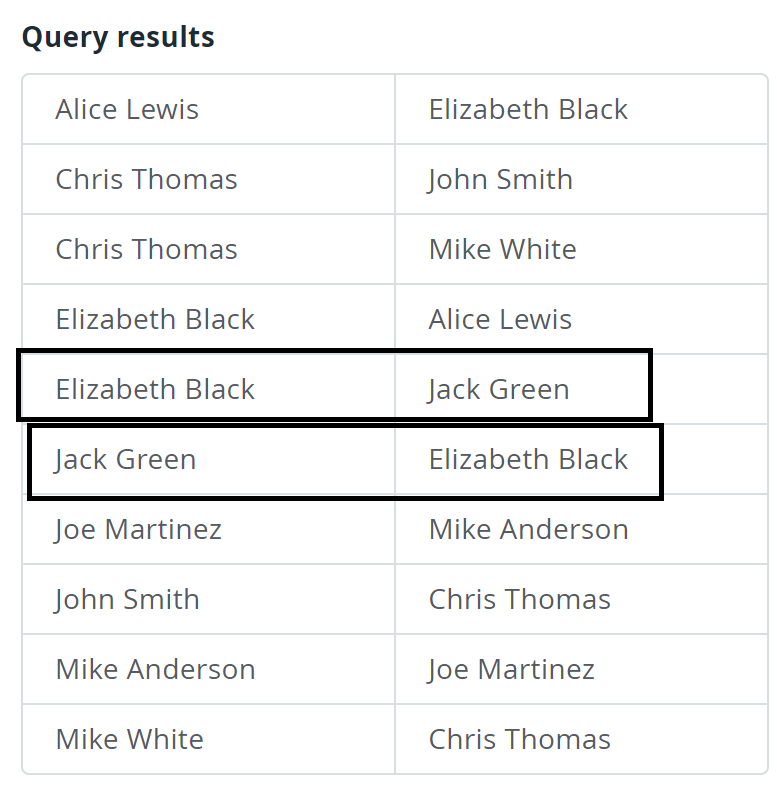
I joined a table with it self and I have repeated pairs as I highlighted in the below image how to remove them?
select DISTINCT A.name as name1 , B.name as name2
from (select name , ratings.* from reviewers inner join ratings on reviewers.id =
ratings.reviewer_id ) A ,
(select name , ratings.* from reviewers inner join ratings on reviewers.id =
ratings.reviewer_id ) B
where A.reviewer_id <> B.reviewer_id
and A.book_id = B.book_id
order by name1 , name2 ASC
| name1 | name2 |
|---|---|
| Alice Lewis | Elizabeth Black |
| Chris Thomas | John Smith |
| Chris Thomas | Mike White |
| Elizabeth Black | Alice Lewis |
| Elizabeth Black | Jack Green |
| Jack Green | Elizabeth Black |
| Joe Martinez | Mike Anderson |
| John Smith | Chris Thomas |
| Mike Anderson | Joe Martinez |
| Mike White | Chris Thomas |
Above table used to be an image
{kind=link}
5
Answers
To remove the repeated pairs from your query result, you can use the GROUP BY clause to group the pairs by name1 and name2, and then select the minimum or maximum value from each group. Here’s an updated version of your query:
In this modified query, I’ve wrapped your original query inside a subquery and used the GROUP BY clause on the outer query. By applying the MIN function on name1 and name2, we select the minimum values from each group, effectively removing the repeated pairs.
Note: It’s important to use an aggregate function (MIN, in this case) when using GROUP BY.
You can just do
See this example
This can be done using
greatestandleastto identify duplicates accross columns :This query will get duplicates :
Result :
Then :
Demo here
To remove the duplicates you first need to find them:
Then you can delete them:
see: DBFIDDLE
I’ve created the DDL and DML statements to reproduce your database and write a query retrieving unrepeated pairs. Here’s the building code which could be of help to others:
And here’s the refactored query:
This is the output you’ll get from it: