


Updated with new table definition
I may be too tired to understand how to achieve the following. I have a table where items refer to each other within the same table. I would like to count how many references each item has.
To simplify I have defined a table of persons where the fathers are linked from their children. The table is created by following:
DROP TABLE IF EXISTS persons;
CREATE TABLE persons (
id INT AUTO_INCREMENT,
isfather TINYINT,
name VARCHAR(20),
father_id INT,
PRIMARY KEY (id));
INSERT INTO persons (name, isfather, father_id)
VALUES ('John', 1, 0), ('Mike', 1, 0), ('Anne', 0, 1),
('Peter', 0, 1), ('Jane', 0, 2), ('Olivia', 0, 1),
('Max', 0, 2), ('Eric', 1, 0), ('Hugh', 0, 0);
SELECT * FROM persons;
This outputs the following table:
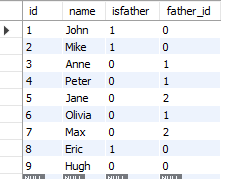
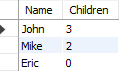
What I would like to achieve is a query that counts how many children each father has. I.e. John has 3, Mike has 2 and Eric has 0:
I have managed to create similar queries, but with two different tables (e.g. a parents table, and a children table). I used SELECT DISTINCT(...), COUNT(...) FROM ... INNER JOIN. But I cannot understand how to use a query with JOIN or similar on the same table. Note that a child must not have a parent, and a parent doesn’t necessarily has a child. I have struggled so long now and my brain is tired to think clearly. I hope somebody can help 🙂
2
Answers
Use a self-join:
Using
LEFT JOINwill get 0 counts for people without any children. Change toINNER JOINif you don’t need them.I would prefer to write this as a simple correlation: