 Question posted in
Question posted in 

I’ve been strugling today Because am trying to remove all the duplicates but it doesn’t work
SELECT DISTINCT pays, nom, count(titre) FROM film JOIN personne ON film.idRealisateur = personne.id GROUP BY nom ORDER BY count(titre) DESC LIMIT 10
OUTPUT
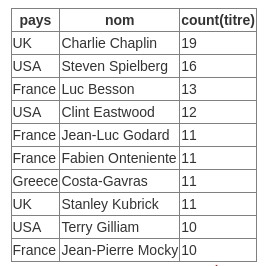
Even When I used DISTINCT I got Duplicates in the column pays
2
Answers
A more clear answer than the comments above:
DISTINCTapplies to all the columns, not just the first column. In your example, you have three rows with apaysvalue of "France", but because they have different values ofnom, the rows count as distinct rows.If you want to reduce the result to one row per value of a specific column, then you should use GROUP BY, not DISTINCT.
I took out
nomfrom this example because if you reduce to one row for the three rows withpays= "France", then what do you want returned as the value ofnom? There are three different values to choose from, and MySQL shouldn’t make a guess at which one you want. For more explanation on this idea, see my answer to Reason for Column is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clauseAs per your table given, it seems like there is a duplicate nom available for the same country. for e.g, As per the first row Pays UK has noms Charlie Chaplin which is the 19th time given in the table as per count(titre).
If you want to remove duplicate rows for a particular column like Pays and noms, we should use Group By with Delete statement.
First of all, perform the query given below.
Then perform Group By statement with Select
Also, attached screen shot with the result to clarify the questions.
Result with removed duplicate rows