


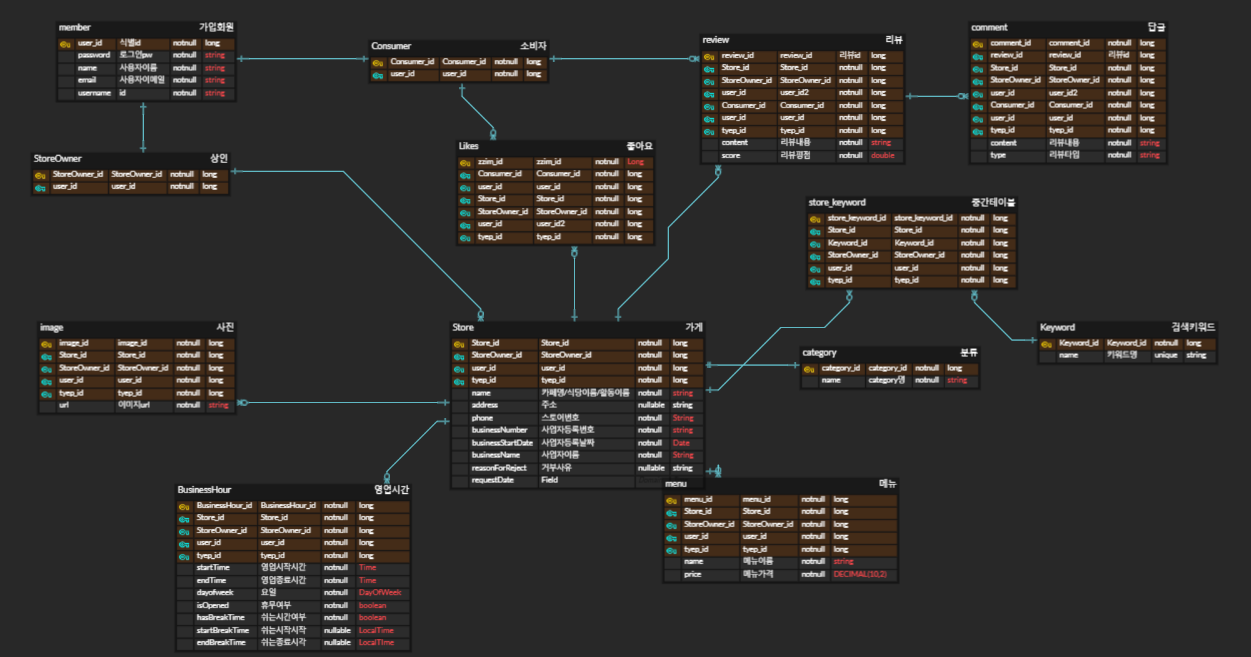
erd as above
{kind=link}
SELECT
store0_.store_id as store_id1_10_,
store0_.address as address2_10_,
store0_.business_name as business3_10_,
store0_.business_number as business4_10_,
store0_.business_start_date as business5_10_,
store0_.category_id as category11_10_,
store0_.name as name6_10_,
store0_.member_id as member_12_10_,
store0_.phone as phone7_10_,
store0_.reason_for_rejection as reason_f8_10_,
store0_.request_date as request_9_10_,
store0_.status as status10_10_
from
store store0_
inner join
category category1_
on store0_.category_id=category1_.category_id
left outer join
store_keyword storekeywo2_
on store0_.store_id=storekeywo2_.store_id
left outer join
keyword keyword3_
on storekeywo2_.keyword_id=keyword3_.keyword_id
left outer join
review reviewlist4_
on store0_.store_id=reviewlist4_.store_id
left outer join
likes likeslist5_
on store0_.store_id=likeslist5_.store_id
where
store0_.status='APPROVED'
AND store0_.name LIKE 'store%'
group by
store0_.store_id
order by
count(reviewlist4_.review_id) ASC LIMIT 100
OFFSET 8000
where condition always has storestatus
Users can search by selecting a few of storename, categoryname, keywordname, and location.
You can sort by store likes, the highest number of reviews, and the highest review rating.
<Tuning Point>
Reduce the number of joins
I can’t reduce it in that situation.. There are many cases where I need the information of the joined table.. Am I doing something wrong with the design..?
If you want to import from there at once, you have to duplicate data from other tables in the store table.
Introduction of index
Storestatus is always the leading condition, so I specified it as an index. However, there are 2-3 types of storestatus values, and most of them are approved stores, so the index effect is insignificant.
Column processing in orderby
In this way, the index will not be removed. If sort is performed, if there is not enough data in memory, it will lead to disk io operation. I know it will have a bad effect on performance, but I can’t help it because I have to sort by the number of reviews.
I can’t help it because I can’t help it. How can I say that I’m going to put my hands on the best query?
Reduce the number of joins
I can’t reduce it in that situation.. There are many cases where I need the information of the joined table.. Am I doing something wrong with the design..? If you want to import from there at once, you have to duplicate data from other tables in the store table.
Introduction of index
Storestatus is always the leading condition, so I specified it as an index. However, there are 2-3 types of storestatus values, and most of them are approved stores, so the index effect is insignificant.
Column processing in orderby
In this way, the index will not be removed. If sort is performed, if there is not enough data in memory, it will lead to disk io operation. I know it will have a bad effect on performance, but I can’t help it because I have to sort by the number of reviews.
2
Answers
EXPLAIN {your query}to see query information and if some indexes may be adjusted or is missing.joinbut withoutleft join; Than separate queries withSELECT {neededInformation} FROM {table} WHERE category_id IN (:idsFromMainQuery).LFET JOINsfor which you are not using any of the columns. This appears to be all butreviewlist4_. (They will be looked at, and the MySQL Optimizer does not seem smart enough to remove them for you.) This seems to be all of yourLEFT OUTER JOINs. As you generate the query, add on the Joins that are needed.LIMIT 100 OFFSET 8000— will be slow. The indexes (even the ones below) will probably not prevent gathering all the potential output rows, skipping over 8000 (one by one), and finally, delivering the desired 100.ON store0_.store_id=reviewlist4_.store_id. If so it may be possible to turn this query inside out — to get theCOUNTsbefore doing all theJOINing, thereby avoiding the costly "explode (Joins) + implode (Group by)".LEFTwithreviewlist4_may be inappropriate; you might get zeros.Tentative indexes:
Many-to-many mapping tables should be optimized by having
two 2-column composite indexes and no auto_inc.
See Optimal relation
Further comments:
It sounds like you need multiple indexes, each being composite and starting with
status.The
ORDER BYcannot be optimized other than by finding a list ofstore_idsbefore gathering all the other stuff. Something like:(this example is probably incomplete and incorrect.)