


DDL & DMLs for creating this table:
Create table If Not Exists Delivery (delivery_id int, customer_id int, order_date date, customer_pref_delivery_date date);
Truncate table Delivery;
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('1', '1', '2019-08-01', '2019-08-02');
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('2', '2', '2019-08-02', '2019-08-02');
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('3', '1', '2019-08-11', '2019-08-12');
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('4', '3', '2019-08-24', '2019-08-24');
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('5', '3', '2019-08-21', '2019-08-22');
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('6', '2', '2019-08-11', '2019-08-13');
insert into Delivery (delivery_id, customer_id, order_date, customer_pref_delivery_date) values ('7', '4', '2019-08-09', '2019-08-09');
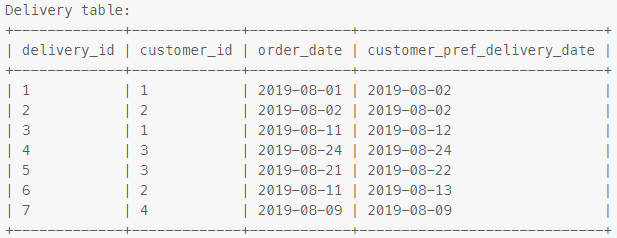
I want to rearrange the rows of this table in ascending order of customer_id and for multiple rows of same customer_id ascending order of order_date.
For getting that I was writing query as:
with t1 as (select *
from delivery
order by customer_id, order_date),
t2 as (select * from t1 group by customer_id)
select * from t2;
and I was getting this table:
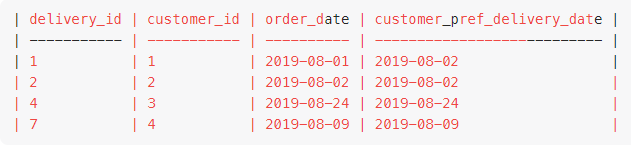
Here in third row instead of 2019-08-24 I was expecting 2019-08-21. Please explain what am I doing wrong in THIS SOLUTION? Please explain why rearrangement is not happening as per the CTE specified?
2
Answers
Your query is unnecessary complicated.
Just select the lowest value for the order date with the MIN() function.
This should work.
Fiddle: http://sqlfiddle.com/#!9/4a8a51/1
The reason why your solution doesn’t work is explained in the comments.
Optimizing Derived Tables, View References, and Common Table Expressions with Merging or Materialization states:
Because
t1is then beinggroupedint2,the optimizer ignores the ORDER BY clause.Your query, and that proposed by SickerDude43, are both nondeterministic. They only return at all because ONLY_FULL_GROUP_BY is disabled. All selected columns (and expressions) should either be in an aggregate function or functionally dependant on the GROUP BY clause.
You should read MySQL Handling of GROUP BY and ONLY_FULL_GROUP_BY.
Here are some typical solutions for greatest-n-per-group:
The aggregate and correlated subqueries will benefit from an index on
(customer_id, order_date).Which one is fastest will depend on the distribution of your data. Give them a try.
Here’s a db<>fiddle.