 Question posted in
Question posted in 

I have a database with a fair amount of duplicated data, i’ve tried a few ways if found on here but struggling with this.
As you can see there are multiple in the ‘owner’ but diferent in ‘type’ and there are some duplicates of both.
End result, i want to delete the duplicated data as an example, id 11,245
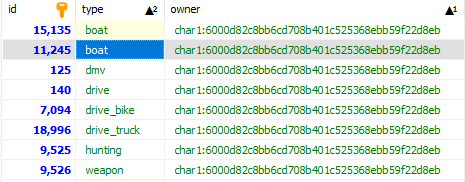
SELECT owner, COUNT(*) type FROM user_licenses GROUP by owner HAVING type > 1
SELECT owner, type FROM table GROUP BY type HAVING COUNT(*) > 1;
2
Answers
I would recommend a self-join:
The subquery identifies the duplicates and their max id, then the outer query deletes rows with the same owner/type and a smaller id.