


I have a csv file which I loaded into MySQL after creating a database and a table (phones). The columns of the table among others are: state and phone_condition. Also, I have ran many queries which were successful; but this one very simple query seem to defy all odds, as I have tried all the solutions here in SO to no avail. Any assistance is highly appreciated. My code:
select state, phone_condition, count(phone_condition) as lagosUsedphones
from phones
where state='Lagos' and phone_condition='Used';
I got
| state | phone_condition | lagosUsedphones |
|---|---|---|
| NULL | NULL | 0 |
When I tried select state, phone_condition from phones where state='lagos' and phone_condition='used'; it returned Empty set (0.01 sec)
I also tried the case statement
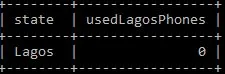
select h.state, count(
case when phone_condition='Used' and state='Lagos' then 1 else null end) as usedLagosPhones
from phones h;
this result: (https://phpout.com/wp-content/uploads/2023/08/66QJQ-jpg.webp)
{kind=link}
Did this too
select count(state and phone_condition) as LagosUsedPhones from phones
where state='Lagos' and phone_condition='Used';
It returned zero.
Meanwhile by inspecting the table, I can see rows where the conditions stated above is true. When I tried to check for null values among the columns using this query select count(*) from phones where state and phone_condition is null; it returned zero, meaning they’re not null values. I can’t understand why this query is not giving the desired result.
EDIT:
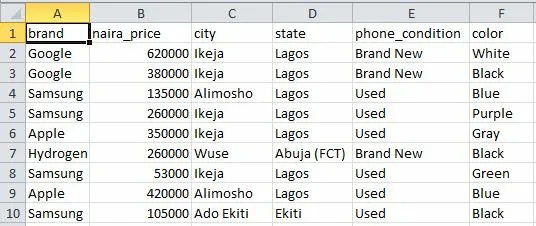
Part of the csv file
2
Answers
If you are combining a COUNT() column with other fields from the target table you need a "GROUP BY" clause, so
Ultimately you’ll need to investigate to figure out what’s going wrong — we don’t have, and you probably can’t give us, enough information to figure it out for you — but I’ll provide a few explanations of what you’re seeing, and some pointers for next steps.
The first thing you have to recognize is that the table you’re querying has no rows where the state is
Lagosand the phone_condition isUsed. I realize that you’ve looked at a CSV file that seems to show such rows; but that still leaves a few possibilities, such as:Lagos, but actually isn’t: for example, maybe there’s whitespace or a control character that we can’t see visually, or maybe one of the characters that looks like a normal Latin character is actually a Cyrillic character or something. (See https://en.wikipedia.org/wiki/O_(Cyrillic).) Or, likewise for the phone condition.Note that
=is case-sensitive, so this is what you would have gotten even if there had been rows with the valuesLagosandUsed.There are two mistakes here:
where state is null and phone_condition is null.So, now, as to why your first query (
select state, phone_condition, count(phone_condition) as lagosUsedphones from phones where ...) showed nulls . . .count(phone_condition), which means that if it didn’t find any rows matching the condition then it had to return a0for that count.count(phone_condition)with regular fields likestate, unless you’re using aGROUP BYclause to aggregate over specific values of that field. MySQL handles this by converting your regular fields likestateto a sort of implicit aggregation that chooses an arbitrary value from the data — like howMINandMAXare aggregations that choose the least and greatest values from the data, respectively, but this implicit aggregation just chooses some value from the data.I think your next steps need to be running queries that help you understand what data your table does contain.
I would start by confirming that the table has roughly the data you expect, with queries like these:
That second query also helps you determine how much data you’re working with, so that you know whether it’s feasible to look through all of it yourself, vs. whether you need to be cleverer with your queries.
If you find that there are a small enough number of distinct states that you can look through all of them, then I’d use this query to do so:
LENGTH('Lagos')is5, so any other value tells you that there are either extra characters or multi-byte characters.CONCAT('<', 'Lagos', '>')is<Lagos>; if you see any spaces after the<or before the>, then you’ll know the problem.And likewise for phone conditions:
If there are too many states or too many phone conditions for this, then you can reduce the result-set size by adding query conditions like
WHERE phone_condition LIKE '%U%'. But be careful with this; any filtering you do has the risk of potentially removing rows that you’re genuinely interested in, because you don’t know exactly what’s wrong with the rows you’re genuinely interested in.Edited to add:
OK, cool. So, yeah, that means that you have something extra before or after the
Lagosor theUsed. I think the most likely possibility is a trailing space afterLagos.