


I have customers and visits table, and I would like to know which of these two queries has the better performance:
(I have indexes defined for those columns)
Query 1
SELECT
customers.id as id,
COALESCE(v.count, 0) as visits
FROM
customers
LEFT OUTER JOIN (
SELECT customer_id, count(*)
FROM visits
GROUP BY customer_id
) as v on visits.customer_id = customers.id
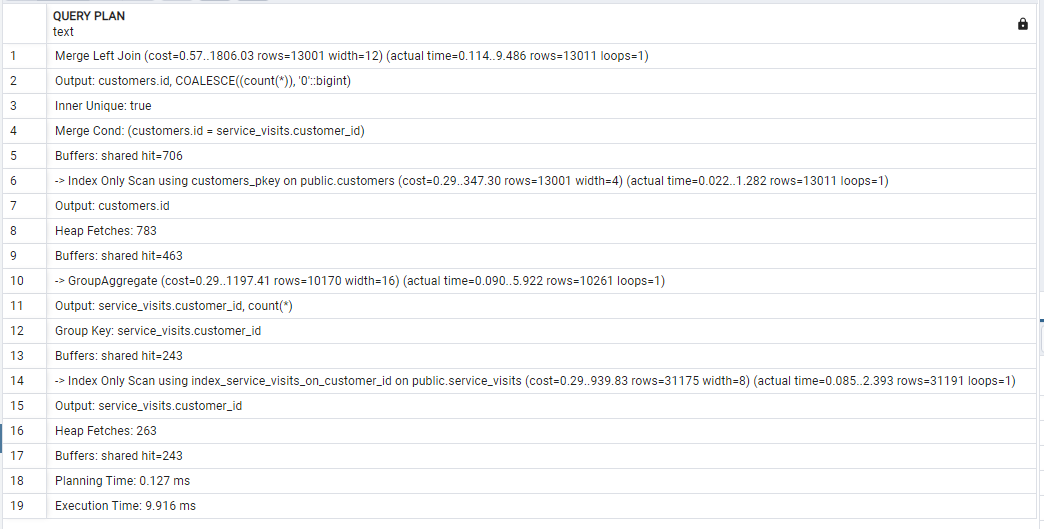
EXPLAIN ANALYZE Result
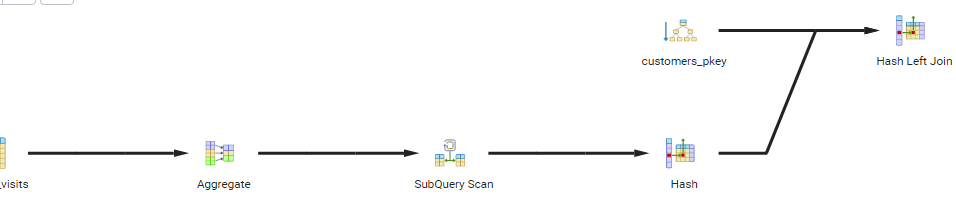
Query 2
SELECT
customers.id as id,
(
SELECT count(*)
FROM visits
WHERE
visits.customer_id=customers.id
) as visits
FROM
customers
EXPLAIN ANALYZE Result
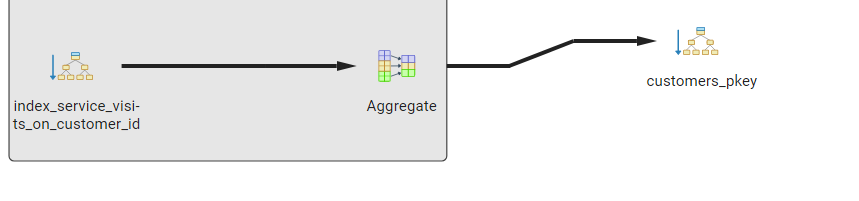

As you see in the above examples the second query has a lower cost, but the excecution time is higher than the first query.
I’m quite confused about it.
I assume that depends on the filter options.
Can you help me to understand that, and if you have a better query, please let me know.
2
Answers
In principle your first one, with the aggregating subquery, is faster than the one with the correlated subqquery. That’s because the aggregate result set can be evaluated just once then hash-joined to the first table.
But the query planner might be smart enough to handle them the same way.
An index on
visits.customer_idwill help.Exactly.
To count visits for all or most customers, the 1st query is substantially faster, as it processes the whole (mostly or all relevant)
visitstable in one fell swoop. Index not required, but an index-only scan may still help.To count visits for a small selection of customers, the 2nd query with a correlated subquery is substantially faster, as it only processes the few rows from table
visitsthat are actually relevant, which outweighs the overhead of running a separate aggregate for each customer. Index required.(Your query plans don’t seem to match the given setup.)
See: