


I’m currently working on a PostgreSQL query to extract specific values from a JSONB column. Here’s the query I’m using:
select
a.id,
(jsonb_array_elements(a.info->'attribute1')->>'value') as attribute1,
(a.info->>'attribute2') as attribute2,
(a.info->>'attribute3') as attribute3,
(jsonb_array_elements(a.info->'attribute4')->>'value') as attribute4
from a_table a
where
(cast(a.info->>'attribute3' as NUMERIC) > 0
or jsonb_array_length(a.info->'attribute1') > 0
or jsonb_array_length(a.info->'attribute4') > 0
or cast(a.info->>'attribute2' as NUMERIC) > 0)
and a.active=true
and a.data='AAA0000'
The problem I’m facing is that it replicates attribute3 as many times as attribute1 (or any other attribute that has more registers), creating incorrect results when I use this query as a subquery to sum all columns’ values.
The result of this query is the following:
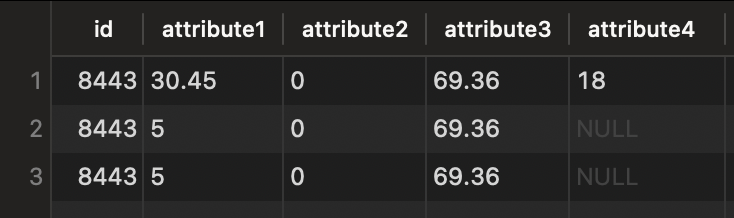
Here’s an example of the data in the info column for the previous result. It can be seen that the previous result is not correct for attribute3.
{
"attribute1": [{"value": 30.45, "description": "abc1"}, {"value": 5, "description": "abc2"}, {"value": 5, "description": "abc3"}],
"attribute2": 0,
"attribute3": 69.36,
"attribute4": [{"value": 18, "description": "aaa"}]
}
I’m looking for a way to modify the query to prevent the replication of attribute values.
2
Answers
One way to avoid this multiplication of rows is to aggregate each produced set into a single array. Like:
Else you get as many rows as the the largest array has elements – in Postgres 10 or later. See:
You’ll need to cast to
numericto "sum all columns’ values". So this alternative sums up values within each array:If you just want to fill in with NULL values, you can wrap the scalar entry into a dummy array and then unnest it just like you do your "natural" arrays. So the 4th line becoming: