


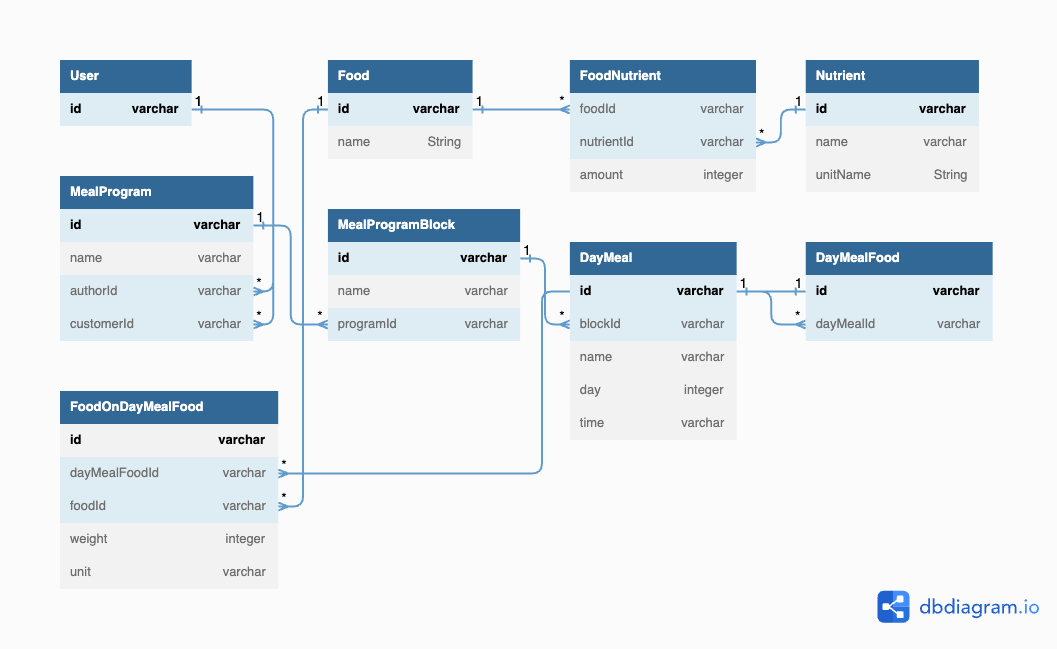
I am designing a DB schema for a meal planning application. Each meal plan consists of blocks (2 months of diet, 2 months of bulking), each block of meals for the day, each meal of the day of foods.
I made a normalized DB schema, however if I wanted to fetch a whole meal plan with it’s analysis, the query would go through more than 6 different tables, which could really slow the application in the future. But I don’t see a way to do it differently. To get the whole meal plan, it would have to through MealProgram > MealProgramBlock > DayMeal > DayMealFood > FoodOnDayMealFood > Food > FoodNutrient > Nutrient.
I know that NoSQL solution could be a fit for this use case, but that’s a no-go in case I need to update a specific nutrient or food, I don’t want to update all the existing records.
Table User {
id varchar [primary key]
}
Table Food {
id varchar [primary key]
name String
}
Table FoodNutrient {
foodId varchar [ref: > Food.id]
nutrientId varchar [ref: > Nutrient.id]
amount integer
}
Table Nutrient {
id varchar [primary key]
name varchar
unitName String
}
Table MealProgram {
id varchar [primary key]
name varchar
authorId varchar [ref: > User.id]
customerId varchar [ref: > User.id]
}
Table MealProgramBlock {
id varchar [primary key]
name varchar
programId varchar [ref: > MealProgram.id]
}
Table DayMeal {
id varchar [primary key]
blockId varchar [ref: > MealProgramBlock.id]
name varchar
day integer
time varchar
}
Table DayMealFood {
id varchar [primary key]
dayMealId varchar [ref: > DayMeal.id]
}
Table FoodOnDayMealFood {
id varchar [primary key]
dayMealFoodId varchar [ref: > DayMealFood.id]
foodId varchar [ref: > Food.id]
weight integer
unit varchar
}
2
Answers
From a comment of yours in the chat we see you’re using Prisma. Unfortunately Prisma does not do JOINs yet. So it actually performs multiple SQL queries on your normalized tables where a bunch of JOINs in a single query would usually not be a performance issue at all – they actually are the foundation of SQL databases.
So, the choice of technology is the culprit here. See also: https://github.com/prisma/prisma/issues/5184
If you can’t find an alternative technology suitable for you and you have to go with Prisma, a denormalization could be an approach.
Updating multiple records for a change of
nutrientorfoodmay feel wrong in the world of RDBMs but a technology not even capable of doing JOINs also is.An alternative could be:
Choose another ORM (if you really need one) that is able to perform JOINs, like sequelize or knex
A more radical alternative could be:
Choose a tool for defining your DDL (database schema) and running migrations, like flyway and write your SQL statements vanilla using the pg client lib.
The data-model so used strongly depends on what kind of database solution is hosting that data . In your case its Postgres and these suggestions are targeted so . If e.g. the database was a MPP one like Teradata it’d be totally different. Having said that here are some pointers .Can grab any that would work for you.
consolidate the
DayMealFoodandFoodOnDayMealFoodtables into a singleMealtable. This would allow you to store all of the information about a meal in a single place, and it would reduce the number of joins you need to perform when fetching a meal plan.Add a
meal_typecolumn to the Meal table. This would allow you to distinguish between different types of meals, such as breakfast, lunch, dinner, and snacks. This information could be used to generate reports and insights about user meal patterns.Add a
meal_plan_idcolumn to theMeal table. This would allow you to associate meals with meal plans, and it would make it easier to fetch all of the meals in a particular meal plan.Add a
created_atandupdated_atcolumn to all of the tables in your data model. This would allow you to track changes to the data over timecomposite primary keyfor theDayMealFood table. Single id value is not very useful for querying the table e.g. to find all of the meals that contain a particular food, need a join of DayMealFood table & Food table.composite primary key(dayMealIdandfoodIdcolumns) would allow you to query the table by day meal or by food without having to join 2 tables.materialized viewfor theMealPlan. improves performance bycachingfrequently used data When a user requests a meal plan, the application could first check to see if the meal plan is in thematerialized view. If the meal plan is in the materialized view, the application can simply return the data from the materialized viewuse a
caching layerto store the data from theDayMealFoodtable. This would allow the application to fetch data from the caching layer instead of the database. This would significantly improve the performance of the application when users request meal plans