


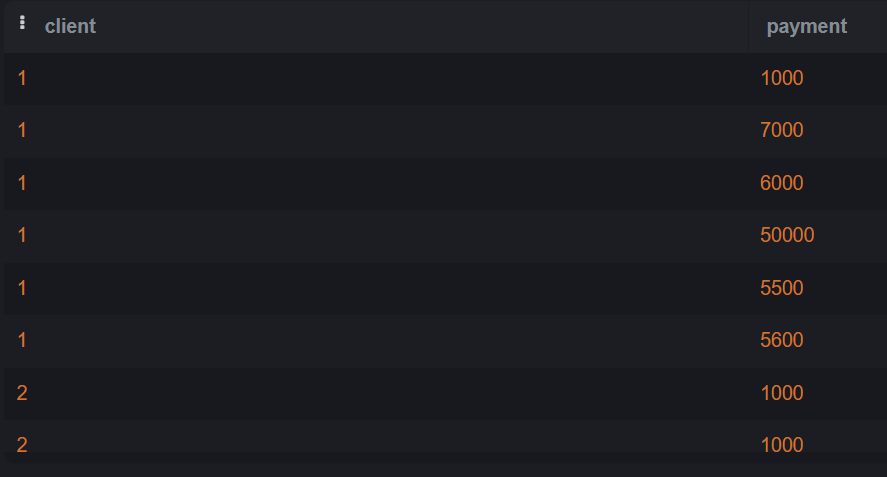
The table
The task is:
Count the number of customers who simultaneously:
{kind=link}
- have more than 5 payments that exeed 5000 dollars
- and have an average payment value of more than 10,000 dollars
I have done it using window function and subquery:
CREATE TABLE Customers (
client INT,
payment INT);
INSERT INTO Customers(client, payment) VALUES
(1, 1000),
(1, 7000),
(1, 6000),
(1, 50000),
(1, 5500),
(1, 5600),
(2, 1000),
(2, 1000);
select client, count(payment) from
(select *, avg(payment) over(partition by client) as avg_payment from Customers) as t1
where payment > 5000
group by client
having count(payment)>5
But I have to make it without window function and subquery. I’ve been told it is possible to do it only with the use of CASE function. I’ll be happy if someone could help me optimize my query.
3
Answers
You can get rid of the subquery by placing the aggregation directly in the
havingclause:(online demo)
I prefer
count(*)overcount(payment)since the latter does not count rows with aNULLvalue, though it doesn’t matter here due to the> 5000condition.Now instead of using
filter, you can use asumthat conditionally counts either1or0per row, and use aCASEstatement for that:or
or
though using
filteris much more elegant and straightforward. See also postgresql – sql – count of `true` values.TLDR: Working fiddle here
Let’s break the query down into pieces:
You can query for payments more then $5,000 in your
WHEREclause, and then specify the "more than 5 payments" in yourHAVINGclause (after aggregating by Client ID):(note that I changed
>5to>=5, since Client ID 1 has exactly 5 matching payments).Then if we wanted to capture "average payment value of more than 10,000 dollars", we’d use a very similar query:
Since these 2 queries are very similar, we should be able to combine them. The only tricky part is we have to get rid of the
payment > 5000from theWHEREclause, since we want to calculate averages for all payments. But wait…it’s a bird! It’s a plane! It’s conditional aggregation to the rescue:We’re not applying the
payment > 5000to theWHEREclause, so we’re getting the average for all payments like we want. But we’re still getting the count of payments > 5000 (COUNT(CASE WHEN payment > 5000 THEN 1 END)), so we can still figure out in theHAVINGclause which clients have 5+ payments of more than $5,000.Technically, based on the question ‘Count the number of customers….’ there isn’t a way of doing this using a single select statement without a join.
It would require either a window function or CTE or subquery to return the aggregation. This is because you cannot run two different groupings within the same selection without a window function (which is required for the initial average and then to count the client IDs)