


My system consists of
- Database (Timescale Db) and table telemetry_aggregations
- .Net Worker nodes (1…n)
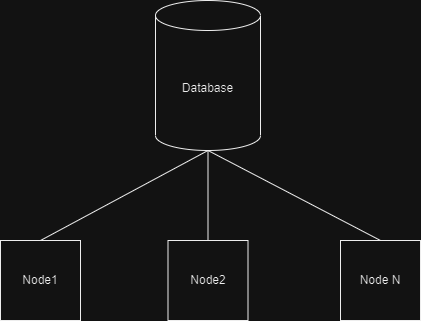
Every couple minutes, telemetry_aggregations table gets updated with couple hundreds of new rows.
How system should work
- Every node periodically requests new batch of data (SQL rows) that haven’t been processed yet.
- Same data (SQL rows) cannot be shared and processed across multiple nodes. If Node 1 gets rows with id 100, 101 … 200, no other services can read/update these rows while Node 1 is processing them. Data processing speed is not guaranteed.
The problem
What sort of architectural pattern or approach should be used to achieve this sort of a system?
I probably need a new table of some sort to keep track of what data has been processed and which haven’t been. I’m suspecting I also need some sort of a lock mechanism which would indicate that this particular row is being worked on and that it should be skipped by other services. But other than that, I am not sure what the best approach to tackle this is.
2
Answers
What you try to achieve sounds a lot like you use your database as some kind of a message / task queue. Not sure this is the best approach. While possible, I’d probably look into task scheduling frameworks, or a messaging solution that supports partitioning, such as Kafka or NATS. That way you can write the metrics to the database (for archiving) and to the message queue for processing. I mentioned the partitioning because that way you can drop different nodes onto different partitions (like using the node id) to make sure that data for the same node is processed by the same processor (and in order of occurrence). I hope this makes sense.
You may want to use SKIP LOCKED for that.
Here’s a nice blog that explains the feature in detail.
And as you said, you will need some info about which rows have been processed. What to do depends on your use-case of course: e.g.
processedto each row (and set it to true after it has been processed)Some additional hints: