


Introduction
The script I am writing reads from a .csv file that has the format of schema, table, column, and then executes a SELECT query to get the values of all records of those columns. My goal with the script is for it to print out all the values of the columns found in the .csv file.
Problem
When running the script, I receive a psycopg2.errors.UndefinedTable error for the cursor.execute() method:
print(f'SELECT "{column}" FROM {schema}."{table}";') # print out query for debugging
cursor.execute(f'SELECT "{column}" FROM {schema}."{table}";')
# Output (Trimmed)
SELECT "CREATION_DATE" FROM abbotsley_271."AREA_BUILD_PHASE_BOUNDARIES";
psycopg2.errors.UndefinedTable: relation "abbotsley_271.AREA_BUILD_PHASE_BOUNDARIES" does not exist
LINE 1: SELECT "CREATION_DATE" FROM abbotsley_271."AREA_BUILD_PHASE...
As you can see from the output, it is complaining that the relation "abbotsley_271.AREA_BUILD_PHASE_BOUNDARIES" does not exist, despite that schema and table do exist in the PostgreSQL database.
If I run the printed query from print() on a DBMS tool like DBeaver, the query works fine:
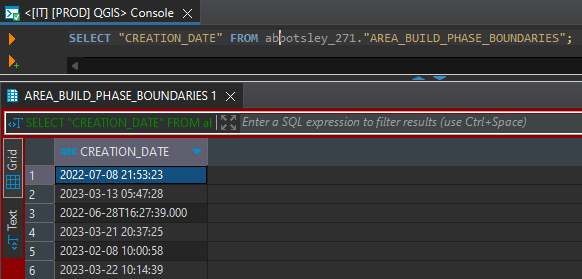
Additionally, if I replace the fstrings in the execute() method with the printed query, it also works fines:
cursor.execute('SELECT "CREATION_DATE" FROM abbotsley_271."AREA_BUILD_PHASE_BOUNDARIES";')
# Output
PS C:Usersuser> & "C:/Program Files/Python311/python.exe" "g:/My Drive/Code Library/Python/Data - character varying to timestamp without time zone.py"
SELECT "CREATION_DATE" FROM abbotsley_271."AREA_BUILD_PHASE_BOUNDARIES";
[('2022-07-08 21:53:23',), ('2023-03-13 05:47:28',), ('2022-06-28T16:27:39.000',), ('2023-03-21 20:37:25',), ('2023-02-08 10:00:58',), ('2023-03-22 10:14:39',), ('2023-06-27 16:38:05',), ('2022-06-28T16:30:33.000',), ('2023-03-21 18:53:04',), ('2022-06-28T16:29:20.000',), ('2023-06-27 16:32:05',), ('2023-01-23 06:27:06',), ('2022-07-04T12:17:18.575',), ('2022-06-28T16:29:01.000',), ('2022-06-28T16:55:00.000',), ('2022-07-04 15:31:46',), ('2022-07-06 12:11:00',), ('2022-07-06 17:00:35',), ('2022-07-07 12:13:04',), ('2022-07-12 00:00:00',), ('2022-07-08 10:55:40',), ('2022-06-28T16:30:42.000',), ('2022-07-12 00:00:00',), ('2022-06-28T16:27:53.000',), ('2022-06-28T16:28:11.000',), ('2022-06-28T16:28:22.000',), ('2022-06-28T16:28:47.000',), ('2022-06-28T16:29:35.000',), ('2022-07-08 21:53:23',), ('2022-07-12 00:00:00',), ('2022-07-12 00:00:00',), ('2022-06-28T16:30:10.000',), ('2022-06-28T16:30:19.000',), ('2023-02-17 06:59:41',), ('2022-07-12 00:00:00',), ('2022-07-12 00:00:00',), ('2022-06-28T16:33:08.000',), ('2022-07-12 00:00:00',), ('2022-06-28T16:29:55.000',), ('2023-03-21 18:33:08',), ('2022-07-12 00:00:00',), ('2023-03-21 18:47:39',), ('2022-07-08 21:53:23',), ('2023-03-21 18:53:04',)]
I would greatly appreciate any insight into this, as I cannot fathom what the issue is.
Full Script
import psycopg2
import csv
from tqdm import tqdm
conn = psycopg2.connect(
host="IP",
database="db",
user="user",
password="password")
cursor = conn.cursor()
with open("C:\Users\user\Downloads\excel_files\character varying to timestamp.csv", 'r', encoding='utf-8') as csv_file:
csv_rows = csv.reader(csv_file, delimiter=',')
columnLengths = []
for value in tqdm(csv_rows, desc="CSV progress"):
schema = value[0]
table = value[1]
column = value[2]
print(f'SELECT "{column}" FROM {schema}."{table}";')
cursor.execute(f'SELECT "{column}" FROM {schema}."{table}";') # error location
data = cursor.fetchall()
print(data)
for record in data:
cvValue = record[0]
columnLengths.append(f"{schema}, {table}, {column}, {cvValue}")
for record in columnLengths:
print(record)
What I Have Tried
- I have tried playing around with the types of encapsulation (
'vs") to no avail - Removed
{schema}.from the query and that avoids the error, but I think this just searches one schema the entire duration of the loop
Update
Error Message
SELECT "CREATION_DATE" FROM "abbotsley_271"."AREA_BUILD_PHASE_BOUNDARIES"
Traceback (most recent call last):
File "g:My DriveCode LibraryPythonData - character varying to timestamp without time zone.py", line 30, in <module>
cursor.execute(tbl_qry.as_string(conn))
psycopg2.errors.UndefinedTable: relation "abbotsley_271.AREA_BUILD_PHASE_BOUNDARIES" does not exist
LINE 1: SELECT "CREATION_DATE" FROM "abbotsley_271"."AREA_BUILD_PHA...
Updated Script
import psycopg2
import csv
from tqdm import tqdm
from psycopg2 import sql
conn = psycopg2.connect(
host="host",
database="db",
user="user",
password="password")
cursor = conn.cursor()
with open("C:\Users\alex.fletcher\Downloads\excel_files\character varying to timestamp.csv", 'r', encoding='utf-8') as csv_file:
csv_rows = csv.reader(csv_file, delimiter=',')
columnLengths = []
for value in tqdm(csv_rows, desc="CSV progress"):
schema = value[0]
table = value[1]
column = value[2]
tbl_qry = sql.SQL("SELECT {} FROM {}").format(
sql.Identifier(column),
sql.Identifier(schema, table)
)
print(f'SELECT "{column}" FROM {schema}."{table}";')
# cursor.execute(f'SELECT "{column}" FROM {schema}."{table}";')
cursor.execute(tbl_qry.as_string(conn))
data = cursor.fetchall()
print(data)
for record in data:
cvValue = record[0]
columnLengths.append(f"{schema}, {table}, {column}, {cvValue}")
for record in columnLengths:
print(record)
2
Answers
Solution
The issue was the encoding that was used to read the
.csvfile was including UTF BOM (byte order mark), which was hidden from print outputs but could be seen with therepr()function (thanks to Adrian Klavian).By changing the encoding to utf-8-sig (found here), in the
with open(encoding=), it removes the BOM and the script runs fine.Working Script
Thanks Adrian Klavian for your help!
Example using sql module: