


I have three tables that are linked together.
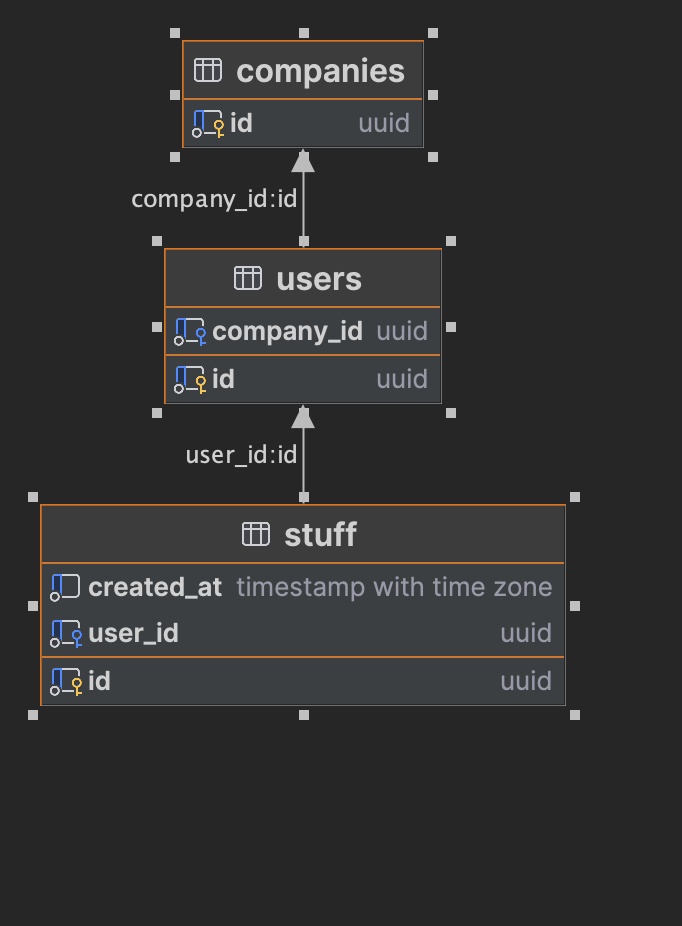
I have stuff table, that has a foreign key to users, that has a foreign key to companies (SQL code of the table and a diagram are at the bottom of the question).
companies table has about ~700 rows in it, users has 30-40 thousand rows and stuff has a couple of million.
Rows in stuff are being inserted daily, about 20-30 thousand, and amount of rows written into it varies drastically from user to user.
Some users can write a few hundred rows today, and then not insert anything new into it for a month. Some users write a few thousand rows every day.
In the app, I have a page that shows the history of stuff order by created_at column and filtered by the company.
Here is the basic query (it can also have an offset):
select s.id
from stuff s
inner join users u on s.user_id = u.id
where u.company_id = 'SOME UUID HERE'
order by s.created_at desc
limit 10;
For some users, that write into the table every day, the query is instantaneous.
For users who rarely write to the table, the query can take up to two minutes.
Here is the query plan with analyze:
QUERY PLAN
Limit (cost=1000.88..4303.03 rows=10 width=24) (actual time=6206.540..9353.007 rows=10 loops=1)
-> Gather Merge (cost=1000.88..5902270.64 rows=17871 width=24) (actual time=6206.539..9353.000 rows=10 loops=1)
Workers Planned: 2
Workers Launched: 0
-> Nested Loop (cost=0.86..5899207.86 rows=7446 width=24) (actual time=6205.840..9352.223 rows=10 loops=1)
-> Parallel Index Scan using "STUFF__CREATED_AT_IDX" on stuff s (cost=0.43..795599.34 rows=4568817 width=40) (actual time=0.026..2942.201 rows=3708817 loops=1)
-> Index Scan using "PK_users" on users u (cost=0.42..1.12 rows=1 width=16) (actual time=0.001..0.001 rows=0 loops=3708817)
Index Cond: (id = s.user_id)
Filter: (company_id = 'SOME UUID HERE'::uuid)
Rows Removed by Filter: 1
Planning Time: 0.336 ms
Execution Time: 9353.056 ms
From what I understand and can see, the nested loop and the sorting step running using parallel index scan are quite slow.
I accidentally ran the query without the limit, and it flipped the problem a bit. For companies that rarely write (and of course have a small amount of data in the stuff table), the query was super fast, but of course, for more active companies it was super slow.
If I remove the sorting, as I expected, the query is super fast, but unfortunately, it’s not what I need.
If I run the query while filtering by user_id, without any joins, I would get this query plan:
QUERY PLAN
Limit (cost=97.22..97.24 rows=10 width=24) (actual time=0.019..0.020 rows=0 loops=1)
-> Sort (cost=97.22..97.43 rows=84 width=24) (actual time=0.019..0.019 rows=0 loops=1)
Sort Key: created_at DESC
Sort Method: quicksort Memory: 25kB
-> Index Scan using "STUFF__USER_ID_IDX" on stuff s (cost=0.43..95.40 rows=84 width=24) (actual time=0.015..0.015 rows=0 loops=1)
Index Cond: (user_id = 'SOME USER UUID'::uuid)
Planning Time: 0.087 ms
Execution Time: 0.040 ms
My guess is that if I add company_id column to stuff table it would yield a similar result (although I am not quite sure).
I don’t have much experience with this sort of optimisation, and it’s a bit difficult for me to understand how and where to start looking.
Can anyone help me try and understand in which direction to dig on how to optimise the query, or maybe help me with the design of the table to improve the query?
Thanks a lot!
Here is the basic structure (columns and tables are renamed due to NDA, and columns are removed for brevity):
CREATE TABLE public.companies
(
id uuid primary key not null default uuid_generate_v4()
);
CREATE TABLE public.users
(
id uuid primary key not null default uuid_generate_v4(),
company_id uuid not null,
foreign key (company_id) references public.companies (id)
);
CREATE INDEX "USER__COMPANY_ID_IDX" on users (company_id);
CREATE TABLE public.stuff
(
id uuid primary key not null default uuid_generate_v4(),
created_at timestamp with time zone not null default now(),
user_id uuid not null,
-- other ~20 fields that are not used in the query
foreign key (user_id) references public.users (id)
);
CREATE INDEX "STUFF__USER_ID_IDX" on stuff (user_id);
CREATE INDEX "STUFF__CREATED_AT_IDX" on stuff (created_at DESC);
EDIT: From further research here’s my understanding of what’s happening in the query plan:
For every row in the stuff table, PostgreSQL joins the users table to that row, and check’s user’s company_id columns. If the value of the column does not equal the one I provided in the condition, it skips the row.
It does that for every row until it finds the amount of stuff provided in the limit (10).
I hope I got it right.
If I made a mistake somewhere, please correct me.
2
Answers
So I got a better result, which is a lot faster than the previous query.
From what I gathered the problem was that Postgres tried to optimise the query, by doing a parallel index scan on
stufftable, joininguserstable and filtering forcompany_idfor every row until it found the correct amount provided in the limit.While that optimisation is amazing for active companies, it didn't work for less active ones.
I tried flipping the query. Instead of looking in the
stufftable, I started at the user's table, which forced Postgres to filter out only the users by the company_id, and only then join them with the stuff table.I'm going to test out the query a bit more, but for now, it seems like a great result.
Thanks @MartinvonWittich for pointing out the obvious, which I missed!
Here is the query that I currently have:
Now kind of results from indexes on
user_idand oncreated_atmust be looped to get the final results. This could be quite slow as you observed.Composed index on
stuffshould solve your problem.